

容器是如何工作的 #
容器的本质是什么 #
笔者之前一直认为容器就是相当于轻量的虚拟机. 虽然容器确实看起来跟虚拟机功能非常相近, 但是实际上这两个东西没有什么关系.
容器实际上是 一组被 Linux 内核用 namespace + cgroup 隔离的进程.
我们可以做一个小实验. 尝试运行一个 fedora 的容器, 并在容器里面运行一个 sleep 进程:
jinbridge@jinbridge-vm:~$ docker run -it fedora:rawhide
[root@602f66756b13 /]# sleep 10000
这时候在宿主机上查找这个 sleep 进程:
jinbridge@jinbridge-vm:~$ ps -ef | grep sleep
root 712069 710391 0 21:36 pts/0 00:00:00 sleep 10000
jinbrid+ 712111 710486 0 21:36 pts/5 00:00:00 grep --color=auto sleep
我们发现这个进程是可以被宿主机观测到的, 尝试查看这个进程的 cgroup:
jinbridge@jinbridge-vm:~$ cat /proc/710391/cgroup
0::/system.slice/docker-602f66756b13a0ea4768465aed4027a7229fb02efcd9d1ae35c9f16d9252f20e.scope
可以看到, 这个就是容器里面的那个 sleep 进程.
正是因为容器的本质是被隔离的进程, 它必须与宿主机共享一个内核.
这也是与虚拟机最大的不同之处: 虚拟机可以拥有自己的内核, 而容器不能.
容器的架构 #
我们可以试着画出容器的架构:
Kubernetes / Docker
↓ gRPC
containerd
↓ OCI Runtime Spec
runc
↓ syscall
Linux Kernel (namespace / cgroup)
我们可以大致分为四层:
- 最上层的应用 (K8s, Docker)
- 为用户提供 CLI 等调用方式
- 统一的管理层 (containerd)
- 管理机器上的所有容器
- OCI Runtime 层 (runc)
- 将容器语义翻译为内核的系统调用
- 内核
应用层 #
应用层负责提供 CLI/API 调用方式. Docker (Docker Engine) / K8s (kubelet) 都跑在这一层. 它们接收来自用户的指令, 并将其翻译为统一的 gRPC 调用发送给下一层.
例如, 当我们尝试运行:
docker run -it fedora:rawhide
Docker 会将这个命令翻译为一个 gRPC 请求 (CreateContainer) 发送给 containerd.
管理层 #
管理层负责统一管理运行的容器. 目前最主流的实现是 containerd. 也有其他的替代品例如 CRI-O, Podman 等.
containerd 在接收到 gRPC 请求之后会生成一个 OCI Runtime Spec 文件 (config.json). 例如以刚才的请求为例:
{
"ociVersion": "1.0.1",
"process": {
"terminal": true,
"args": ["/bin/bash"],
"env": ["PATH=..."]
},
"root": {
"path": "rootfs"
},
"linux": {
"namespaces": [
{"type": "pid"},
{"type": "mount"},
{"type": "net"},
{"type": "uts"},
{"type": "ipc"}
],
"resources": {
"memory": {},
"cpu": {}
}
}
}
这里便是完整的容器语义. 接下来就是将这个配置下发给运行时来执行.
容器的网络与存储都是在这一层完成配置的.
在提交给运行时 Spec 文件之前, 管理层会创建完容器需要的一切 (存储, 网络等).
值得一提的是 containerd 的原生 gRPC 并不是 CRI 格式.
K8s 在调用 containerd 时需要 CRI Plugin 将其翻译为原生的 gRPC 格式.
containerd 与 CRI
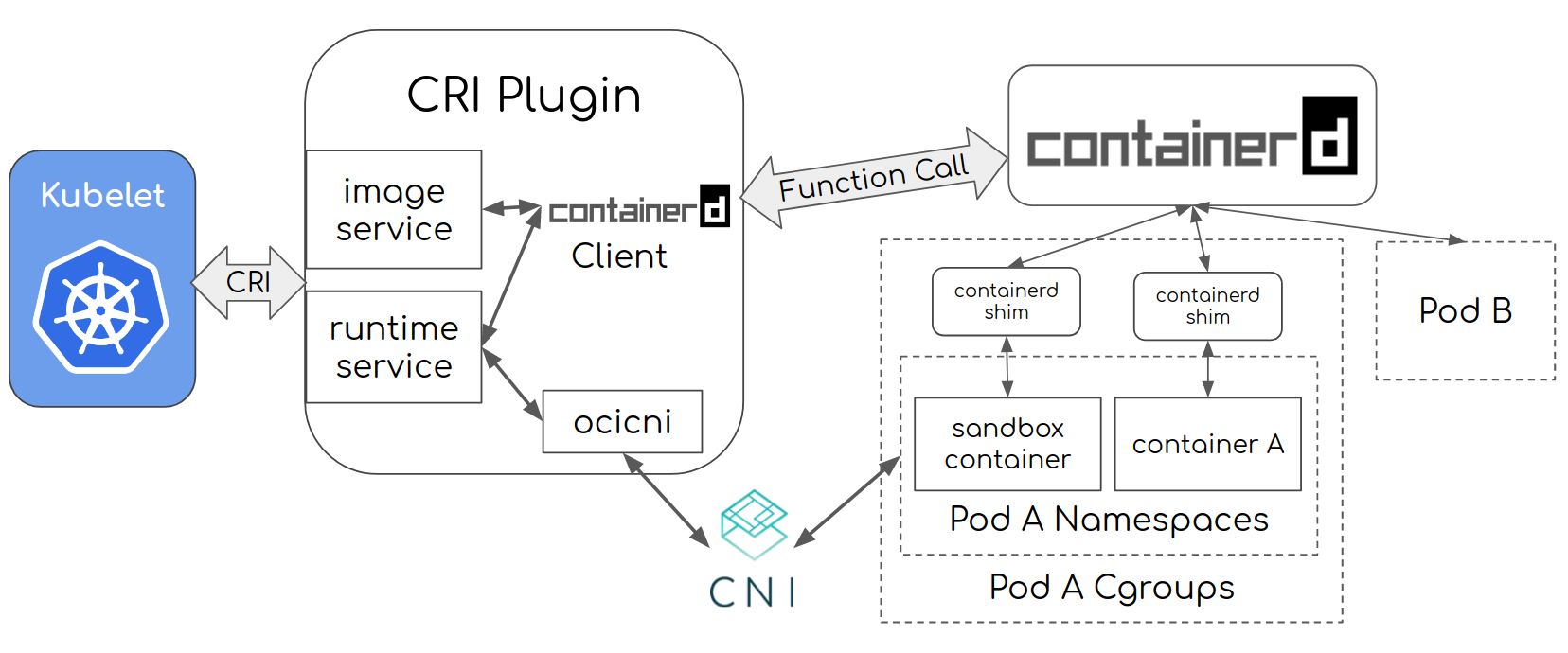
运行时 #
运行时负责根据给定的容器语义创建具体的进程. 这一层最主流的实现是 runc.
以刚才的请求为例, runc 会执行以下的操作:
- 创建对应的进程 (
clone). - 在新的进程中:
- 挂载文件系统 (
mount,pivot_root,unmount等) - 执行具体的应用 (
execve)
- 挂载文件系统 (
内核 #
内核负责实现最后的一切. 包括文件系统隔离, 网络隔离, 资源限制等.
内核的隔离与限制机制 #
内核依靠 namespace 与 cgroups 来隔离与限制进程.
namespace #
namespace 实现了视图隔离.
常用的 namespace 包括:
- PID namespace (PID): Responsible for isolating the process (PID: Process ID).
- Network namespace (NET): Manages network interfaces (NET: Networking).
- IPC namespace (IPC): Manages access to IPC resources (IPC: InterProcess Communication).
- Mount namespace (MNT): Responsible for managing the filesystem mount points (MNT: Mount).
- uts namespace (UTS): Isolates kernel and version identifiers (UTS: Unix Timesharing System).
- usr namespace (USR): Isolates user IDs, meaning it separates user IDs between the host and container.
- Control Group namespace(cgroup): Isolates the control group information from the container process.
拥有相同 namespace 的进程共享相同的视图. 例如如果两个进程的 Mount namespace 是一致的, 那么它们能看到的文件系统就是一致的.
cgroups #
cgroups 全称 Control Groups, 是内核提供的物理资源隔离机制. 通过这种机制, 可以实现对 Linux 进程或者进程组的资源限制.
常见的资源限制包括:
cpu/cpuacct: CPU 时间分配、统计cpuset: 限制使用哪些 CPU 核memory: 内存限制、OOM 行为blkio/io: 磁盘 IO 限速pids: 限制进程数量devices: 设备访问控制freezer: 挂起 / 恢复进程组net_cls: 网络流量分类
举个例子, 假如我们想要限制某个进程使用不超过 100MB 内存, 那么可以执行下面的命令:
mkdir /sys/fs/cgroup/demo
echo $((100 * 1024 * 1024)) > /sys/fs/cgroup/demo/memory.max
echo PID > /sys/fs/cgroup/demo/cgroup.procs
参考资料 #
- What is a Container and How Does it Work? https://devopscube.com/what-is-a-container-and-how-does-it-work/