

Memory 相关工作 #
最近看了些 Memory 相关的论文, 整理一下.
什么是 Memory? #
Memory 算是后训练的一部分. 是一个很宽泛的概念.
一种分类方法是, 按照长期/短期记忆与显式/隐式记忆来区分. 可以绘制一个坐标轴.
这种分类认为:
- 局限于当前对话的 Memory 是短期的, 对应的长期 Memory 则是贯穿当前与后续对话.
- 人为外挂的, 结构化, 可阅读的 Memory 是显式的, 而模型内部的, 无法人为阅读的则是隐式的.

RAG #
一种主流的方式是将记忆从 LLM 中分离出去, 存到数据库里面. 这种方式具有可解释性, 且实现起来相对容易.
最简单的方式是人工将记忆进行处理, 分块用 embedding 进行索引. 生成时加入到上下文中. 另一种方式是让模型自己来处理记忆. 例如 Mem-0 将模型的历史对话进行总结存储到数据库中, 由模型决定什么时候进行 CRUD 操作. Mem-α 则对记忆的操作进行了 RL 训练.
Memory Editing #
也有工作尝试修改模型的参数来改变 Memory. 有观点认为模型的记忆存储在 transformer 的 MLP 层. MLP 的两层结构 $(W_{fc}, W_{proj})$ 可以看成是:
- 前半部分: 将输入映射到一个 key 表示 $k$
- 后半部分: 通过 $W_{proj} k \rightarrow v$ 来进行检索.
基于这方面的工作有 ROME, MEMIT 等, 通过根据 $k$ 与 $v$ 修改 MLP 层的 $W$ 来修改特定的记忆. 通过对不同 MLP 层进行修改, 可以做到插入大量的记忆 (> 10000 条).
Steer #
Steer 是一种操作短期隐式记忆的范式, 直译过来叫做「驾驶」. 相当于直接操纵 LLM 的内部隐藏状态来控制输出.
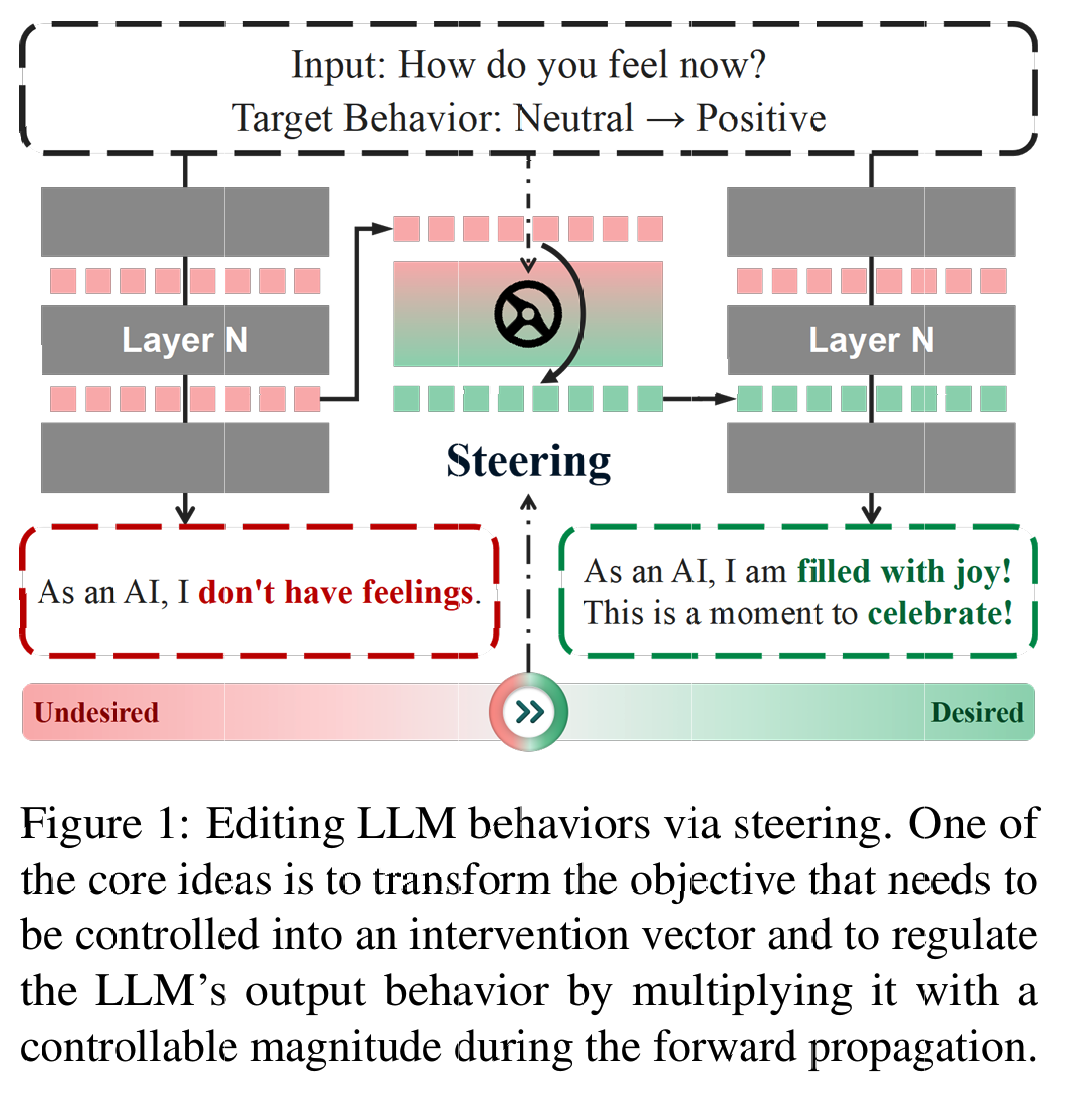
笼统的来说, 就是寻找一个 Steer 向量 $v$. 在推理的时候, 通过直接将 Steer 向量加在激活层上来控制模型的输出. $$h’ = h + \alpha v$$ 其中 $\alpha$ 是控制强度.
Steer 向量的构造方式有很多种, 一种是 CAA, 通过正负样本对比生成, 具体的流程是
- 让 LLM 对一个正样例与一个负样例各自推理
- 在提取某一激活层 $h$, 相减得到 Steer 向量: $$v=E(h^{pos}) - E(h^{neg})$$
另一种是 STA, 用 Sparse AutoEncoder 提取更细粒度的 Steer 向量: $$v=SAE(h^{pos} - h^{neg})$$ 具体而言, 就是用 SAE 的 decoder 列向量作为细粒度的 Steer 向量.
还有一种方式是 LM-Steer. 核心是: LLM 的输出词向量(output word embeddings)实际上蕴含着“生成风格方向(style steer)”。 对它们做线性变换,相当于改变语言模型的生成风格。
可以理解为直接对最后的输出层做调整: $$e_v^’ = (I+\epsilon W) e_v $$ 其中 $W$ 通过对比的方式进行训练. 对于正样本训练 $+\epsilon W$, 对于负样本训练 $-\epsilon W$
KV Cache #
也有工作探讨直接从 KV Cache 层面进行 Memory 相关的工作. 例如, Memory3 提出了一种方法, 将 reference 预处理为 KV 对, 推理时直接拼接到模型的 KV 后面.
模型结构几乎保留普通 Transformer,只新增:
- 写入显式记忆(不需要训练)
- 在自注意力中读取显式记忆(concat 到 KV) 某种意义上类似于将本来存放在参数里面的知识抽到外面存储.