语音表征相关论文整理 #
对语音表征做个简单的分类 #
语义 or 声学 #
- 语义表征: 词义, 句子含义等. 无论谁说「今天天气不错」, 语义基本一致
- 声学表征: 频率, 能量, 长度等声学表征. 同一句「你好」, 不同人说 (男声/女声/儿童) 声学表征会明显不同.
- 还有一种常见的做法是将语义表征与声学表征做各种不同的融合.
离散 or 连续 #
- 离散: 对提取的表征进行量化. 比如 VQ, RVQ 等方法.
- 离散: 不对表征进行量化. 表征空间是连续的.
声学连续表征 #
[19.04] wav2vec #
wav2vec 算是语音自监督语义表征的代表之作. 核心在于将自监督学习第一次搬到语音上并成功应用于下游任务.
wav2vec 主要分为两个部分: Encoder $f: \mathcal{X} \mapsto \mathcal{Z}$ 与 Context Network $g: \mathcal{Z} \mapsto \mathcal{C}$. 类似一个两层的卷积.
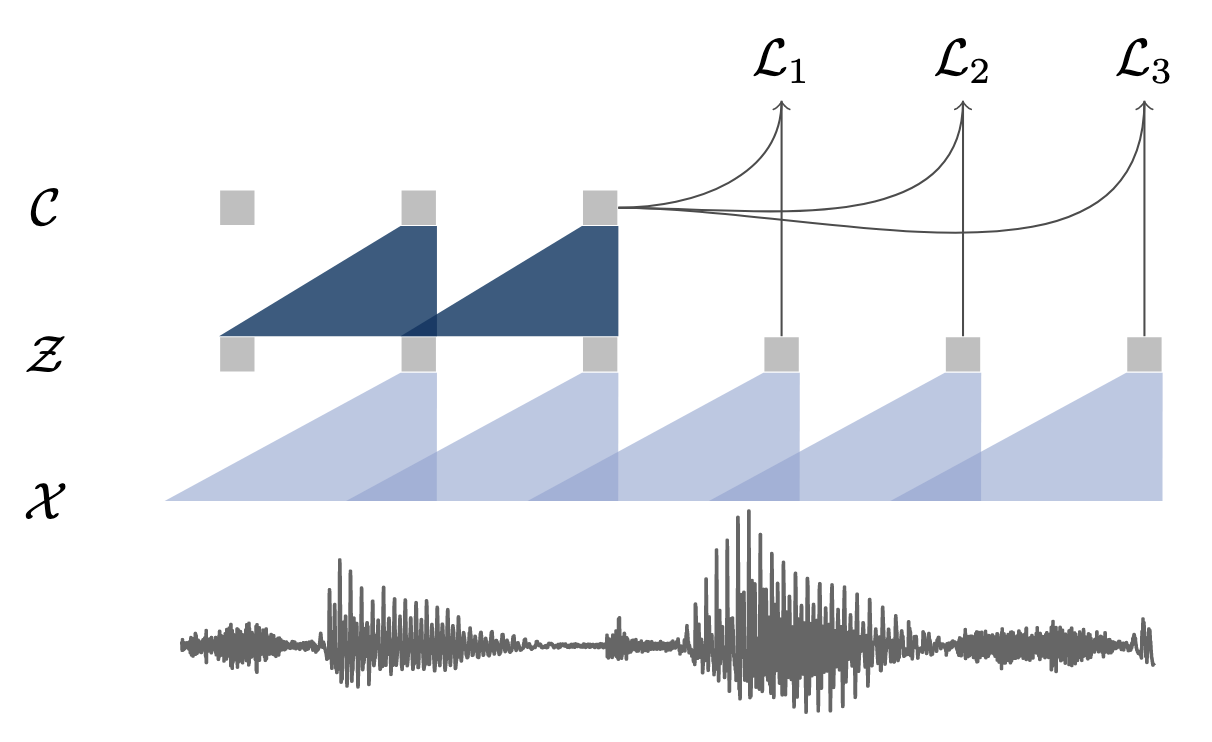
训练的损失函数为:
$$ \mathcal{L}_k = - \sum_{i=1}^{T-k} \left( \log \sigma\left(\mathbf{z}_{i+k}^\top h_k(\boldsymbol c_i)\right) + \lambda \mathbb{E}_{\tilde{\mathbf{z}} \sim p_n} \left[ \log \sigma\left(-\tilde{\mathbf{z}}^\top h_k(\boldsymbol c_i)\right) \right] \right) $$其中的:
- $h_k(\boldsymbol{c}_i)$ 是一个线性层, 也就是 $h_k(\boldsymbol{c}_i)=W_k\boldsymbol{c}_i + \boldsymbol{b}_i$
- $\sigma\left(\mathbf{z}_{i+k}^\top h_k(c_i)\right)$ 是用来表示 $\mathbf z_{i+k}$ 是正样本的概率.
最终的损失为 $\mathcal{L} = \sum_k \mathcal{L}_k$
[20.06] wav2vec 2.0 #
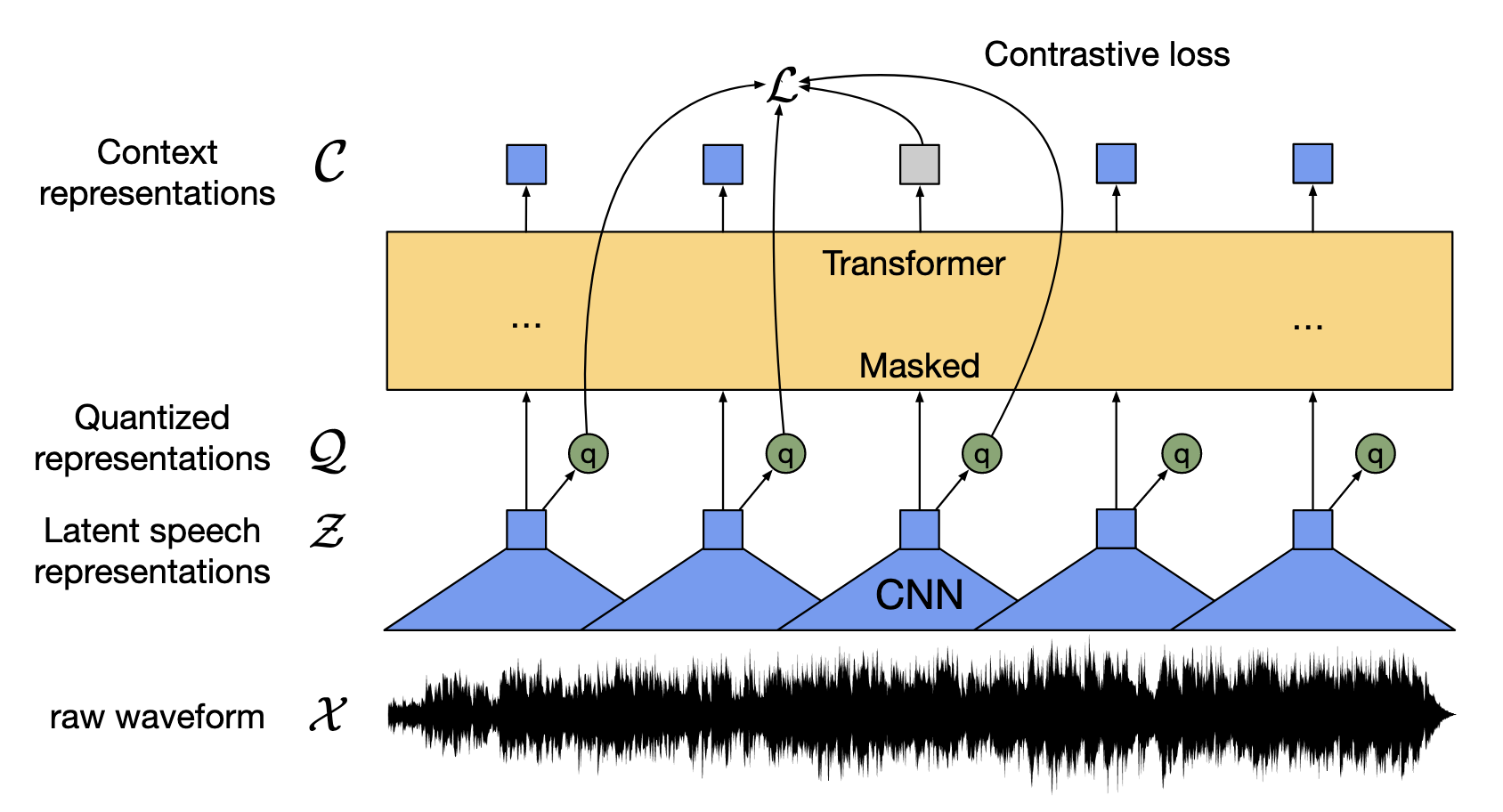
wav2vec 2.0 仍然保留了一个 Encoder. 但换用了 Transformer 建模上下文, 并在训练的时候对隐向量进行量化.
为什么训练需要量化
量化将隐空间缩小, 相当于变成了一个标签, 强迫模型学习具体的语义而非细节.
训练时采用了类似 BERT 的掩码训练.
具体的损失函数为:
$$\mathcal{L} = \mathcal{L}_m + \alpha \mathcal{L}_d$$其中主要部分是 Contrastive Loss
$$\mathcal{L}_m = -\log \frac{\exp(\mathrm{sim}(c_t, \mathbf{q}_t)/\kappa)}{\sum_{\tilde{\mathbf{q}} \sim Q_t} \exp(\mathrm{sim}(c_t, \tilde{\mathbf{q}})/\kappa)}$$用了类似对比学习的方式, 尽量让 $c_t$ 接近该位置 $q_t$ 的表示
另一部分是 Diversity loss, 最大化 codebook 使用分布的熵, 从而防止模型量化时只选同几个 codeword:
$$\mathcal{L}_d = \frac{1}{GV} \sum_{g=1}^{G} -H(\bar{p}_g) = \frac{1}{GV} \sum_{g=1}^{G} \sum_{v=1}^{V} \bar{p}_{g,v} \log \bar{p}_{g,v}$$[21.06] HuBERT #
HuBERT 做了一个改进: 语素标签可以通过聚类直接生成, 而不需要学习.
论文里面基于梅尔谱将帧级别的音素分为了 500 个类别. 类比到 LLM 就相当于有 500 种 token.
这样就可以用 BERT 的方式来进行训练. 对应的 Loss 也就是
$$ L_m(f; X, M, Z) = \sum_{t \in M} \log p_f(z_t \mid \tilde{X}, t) $$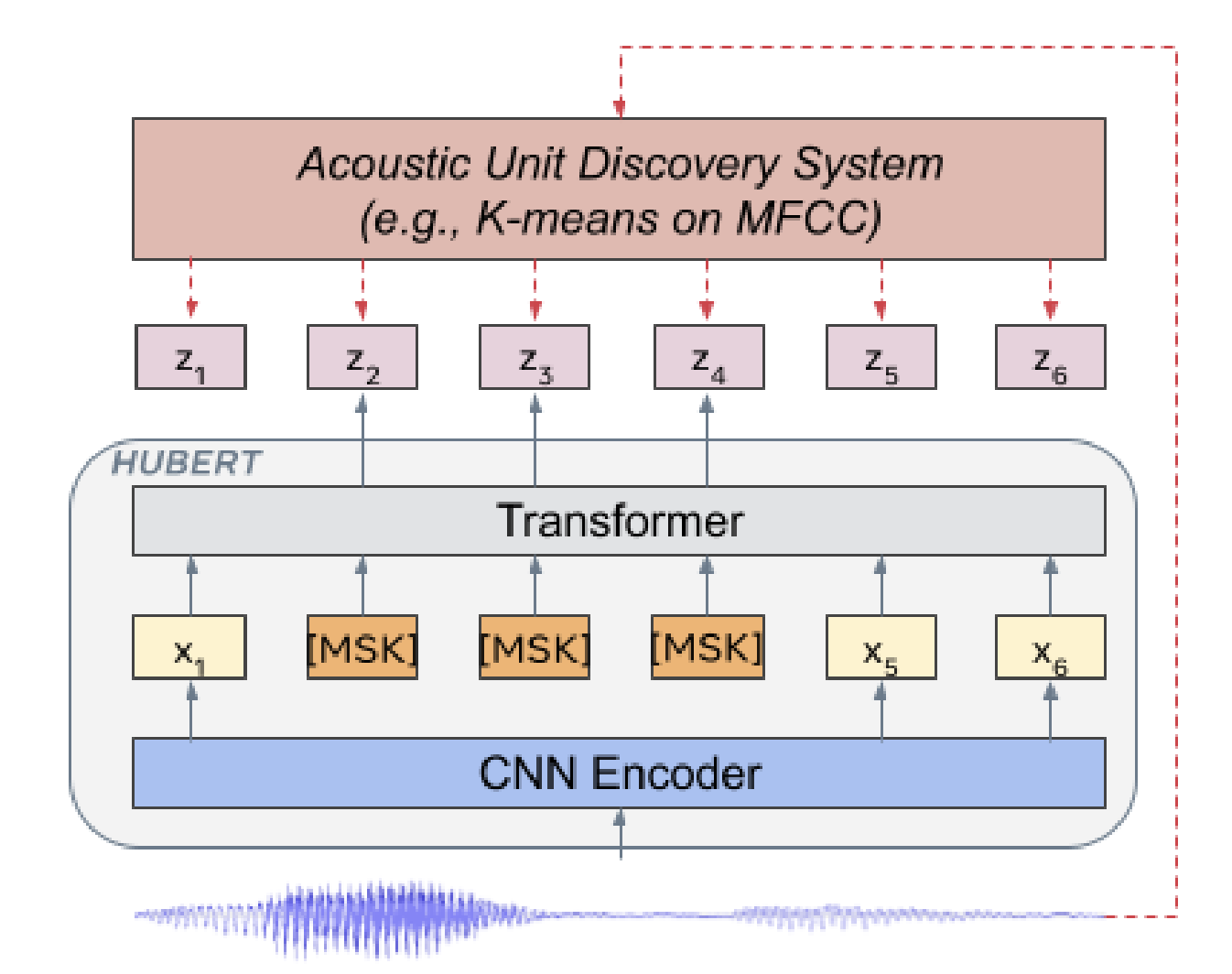
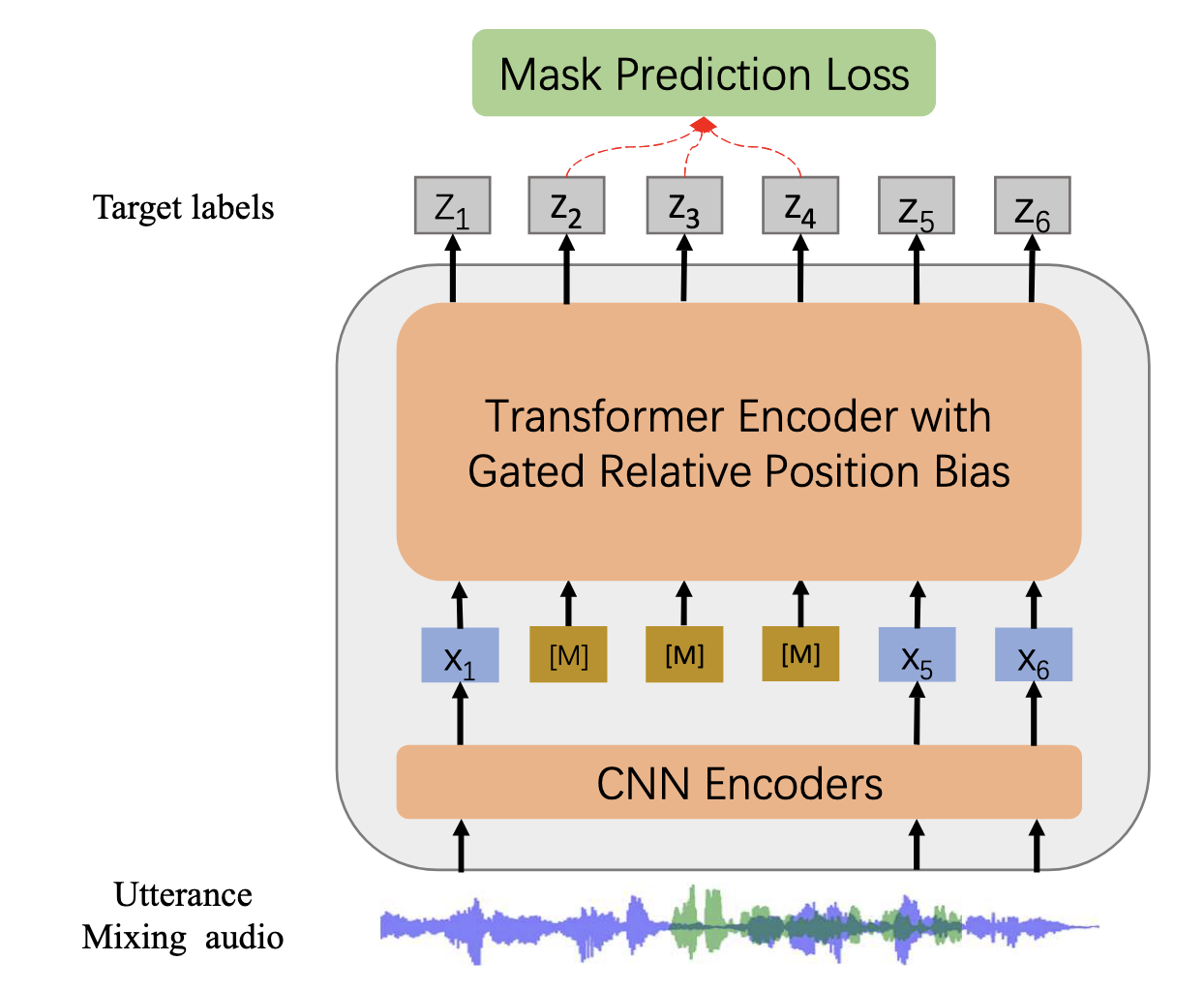
[21.10] WavLM #
WavLM 在 HuBERT 的基础上做两个改进:
- 将原始的音频加噪声, 让模型预测干净的音频.
- 在原始的 Attention 公式里面加了个相对位置偏置, 从而强化相对位置信息.
声学离散表征 #
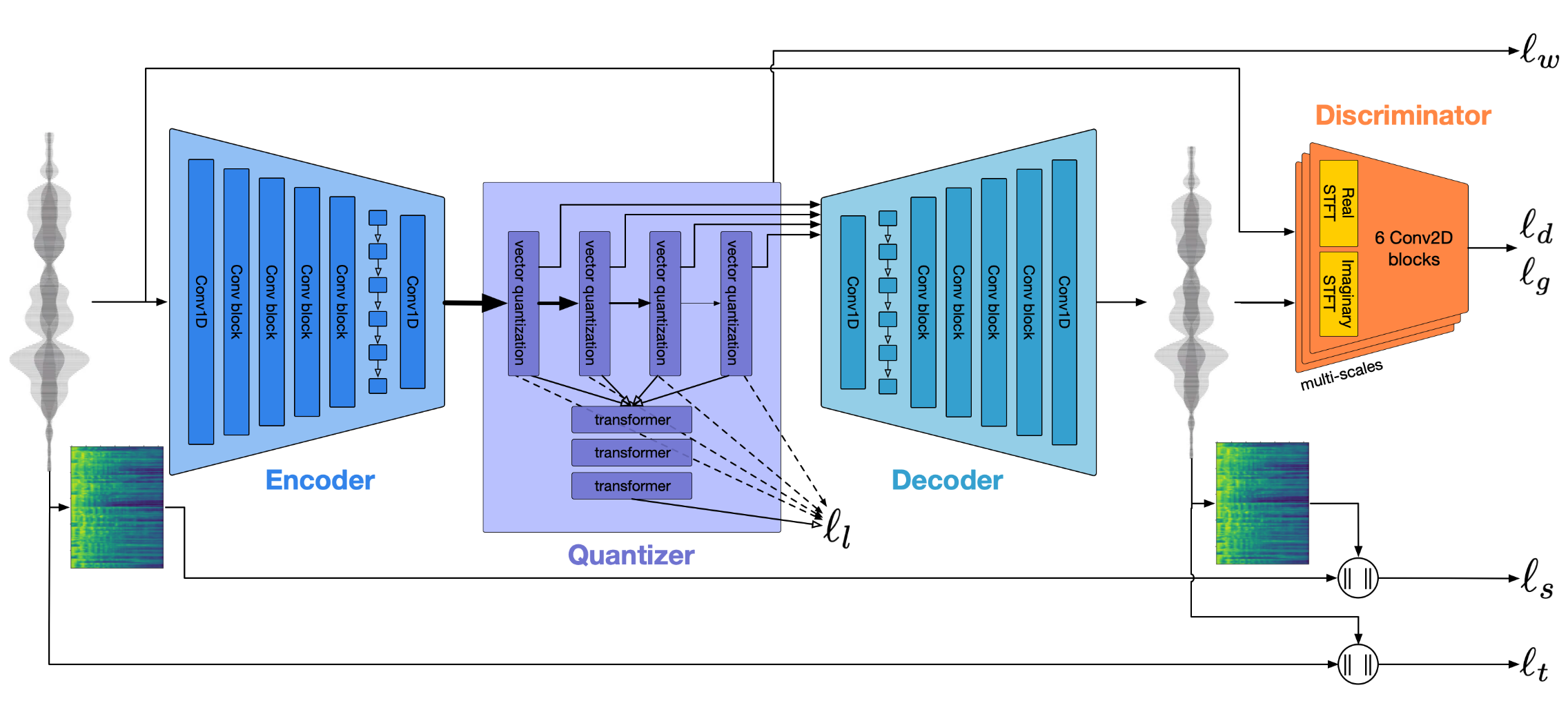
[22.10] EnCodec #
EnCodec 是 Meta 提出的一个高音质、低码率、可实时运行的音频压缩器.
核心创新点有:
- 残差向量量化 (RVQ). 不是一次量化, 而是逐步逼近. 从而实现更高精度.
- 采用了 GAN 的思路, 加了个多尺度 STFT discriminator.
- 采用多个 Loss 组合. 并且分配时不分配 Loss 而是分配梯度.
语义连续表征 #
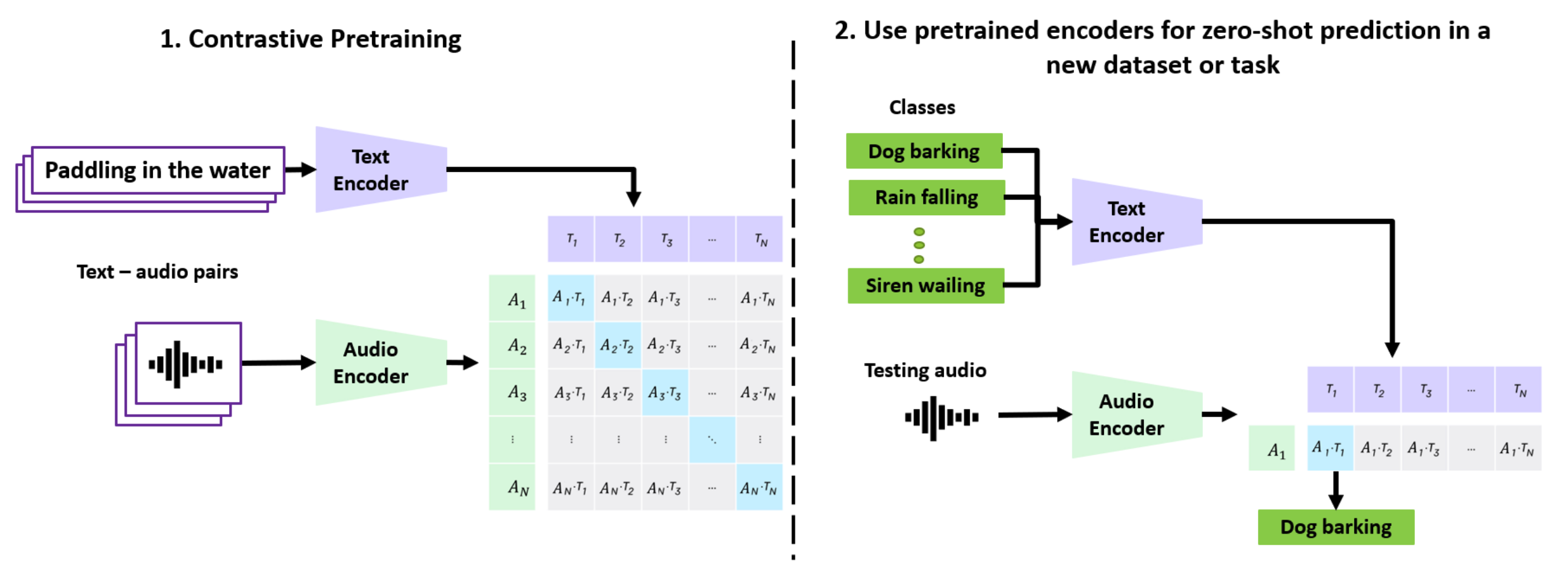
[22.06] CLAP #
CLAP 属于是将 CLIP 搬到音频上.
除此之外的一个核心创新是用自然语言 caption 代替了 label.
- 传统的音频数据:
dog_bark - CLAP 使用:
a dog barking loudly in the park
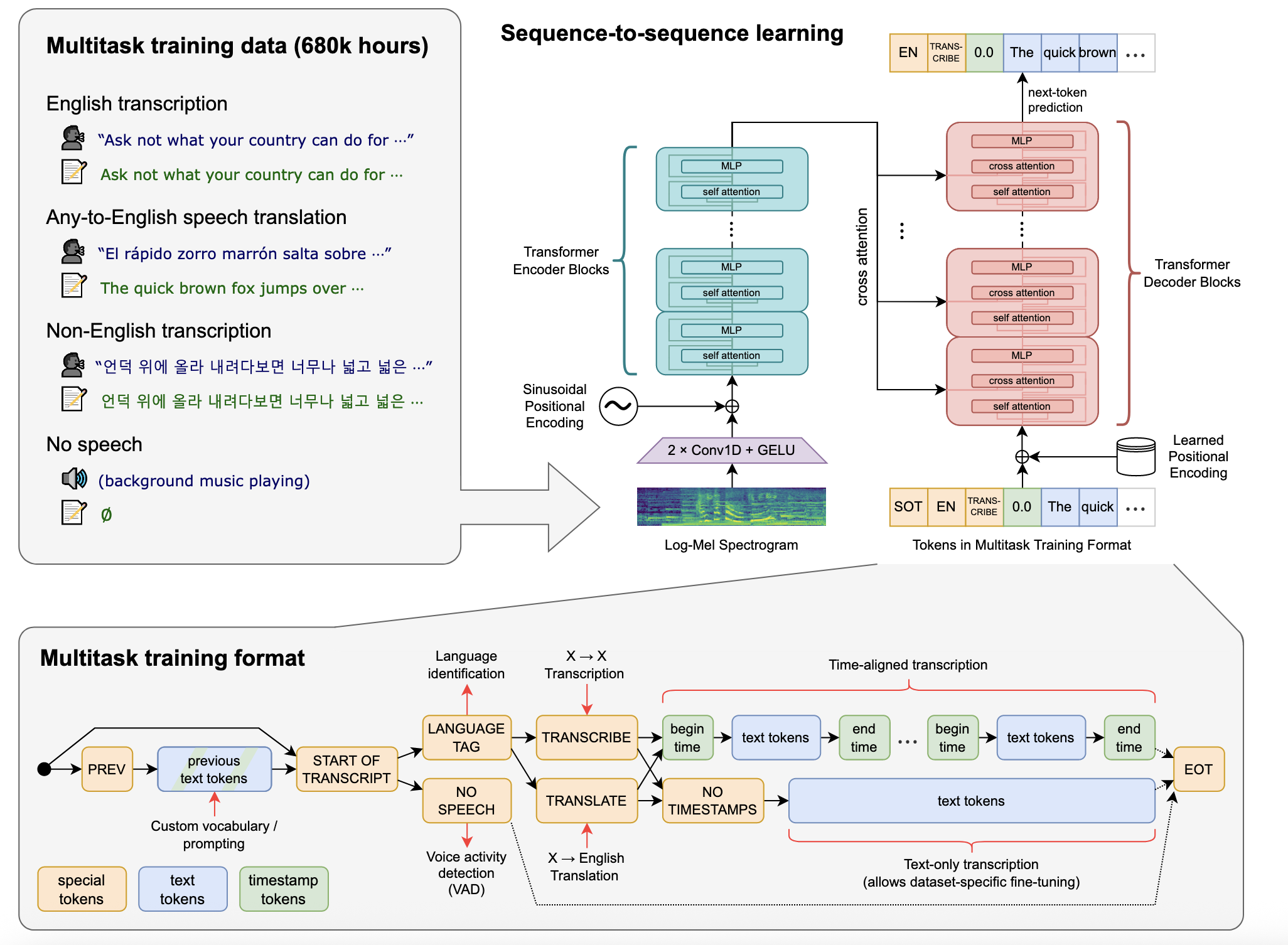
[22.12] Whisper #
Whisper 用大量的弱标注数据 + 直接端到端训练做了一个无需微调, 开箱即用的语音模型.
核心在于:
- 模型结构上面使用了 Encoder-Decoder 架构. Decoder 采用了交叉注意力来注入语音信息.
- 用 token 告诉模型任务的类别.
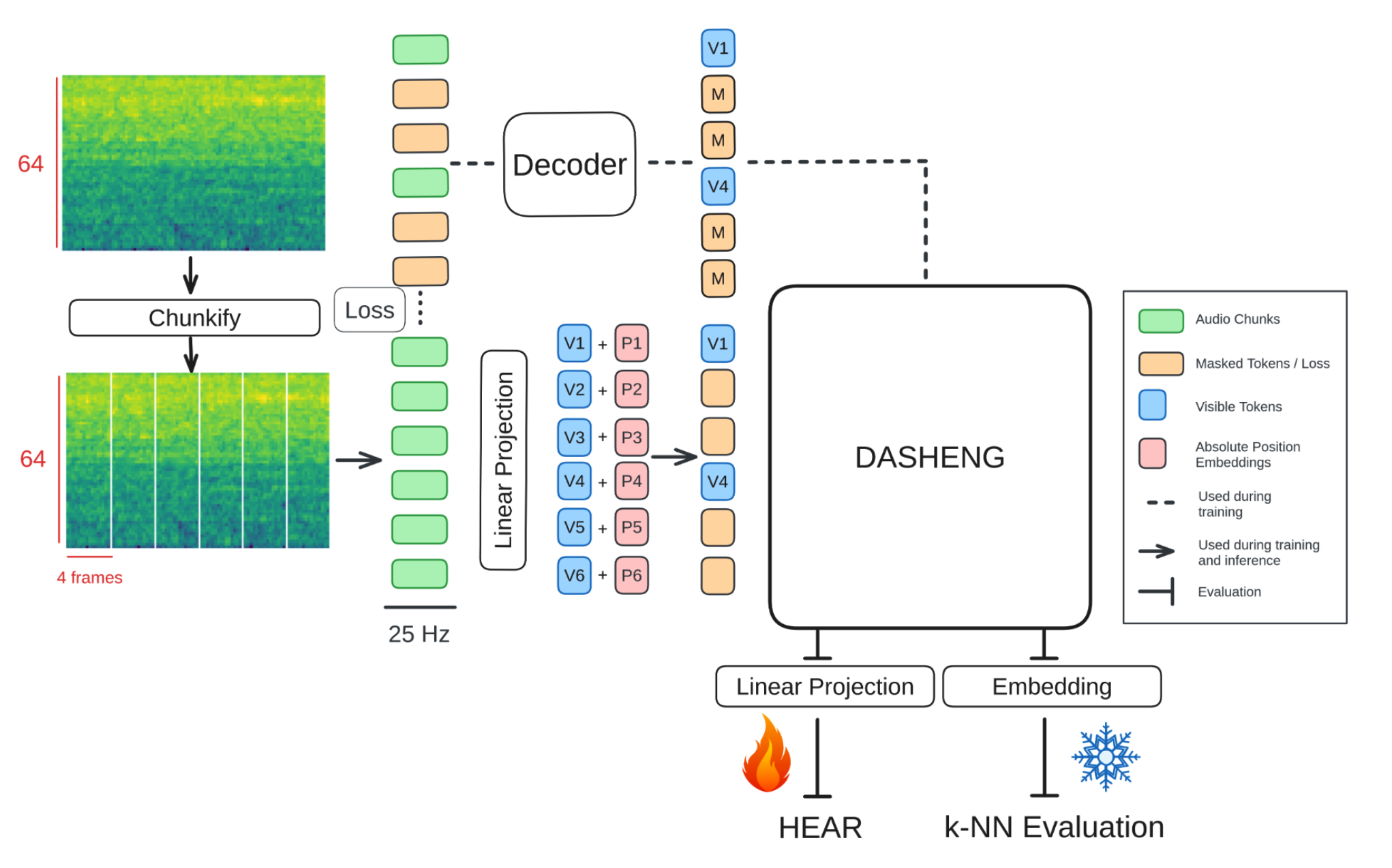
[24.06] Dasheng #
Dasheng 是小米提出的一个音频 encoder. 核心是一个 Transformer-based MAE.
比较关键的创新点是在音频 encoder 上做了 scaling law 的验证.
语义离散表征 #
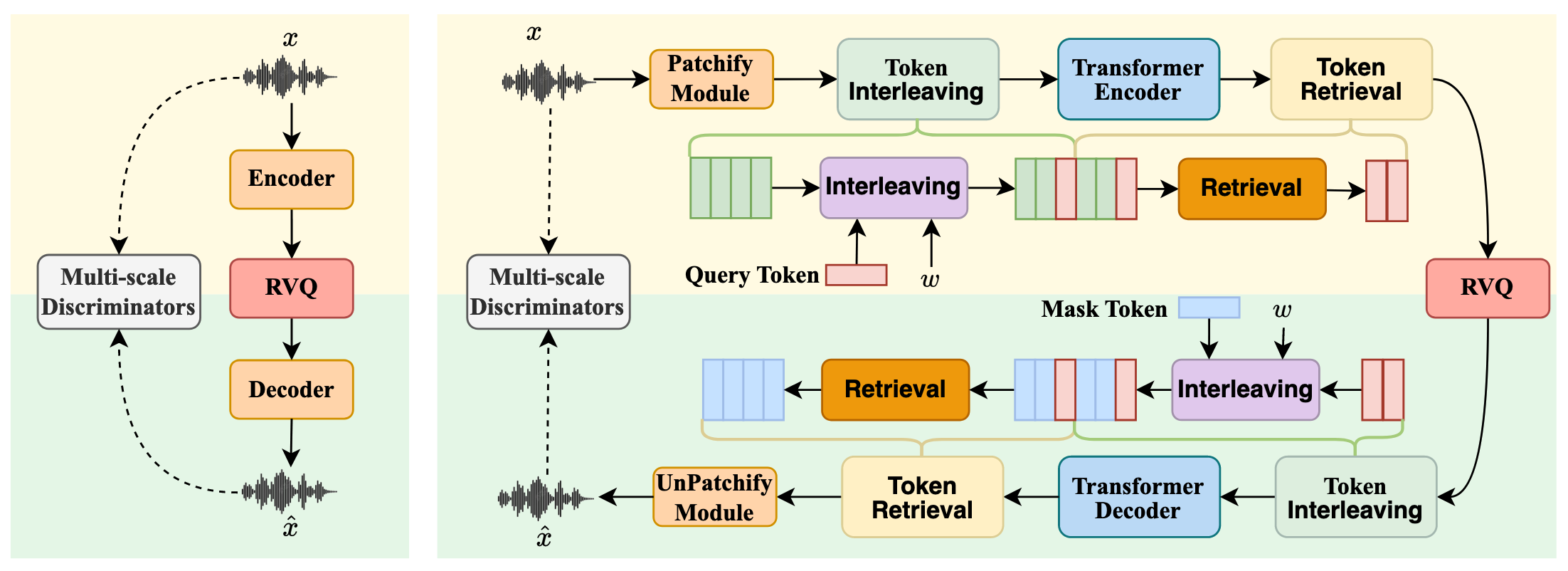
[25.04] ALMTokenizer #
ALMTokenizer 尝试在尽可能保留语义表征能力的同时提高压缩率.
最核心的创新在于用 transformer 将原始的语义注入到 query token 里面. 从而在保留语义能力的同时做到更少 token.
混合离散表征 #
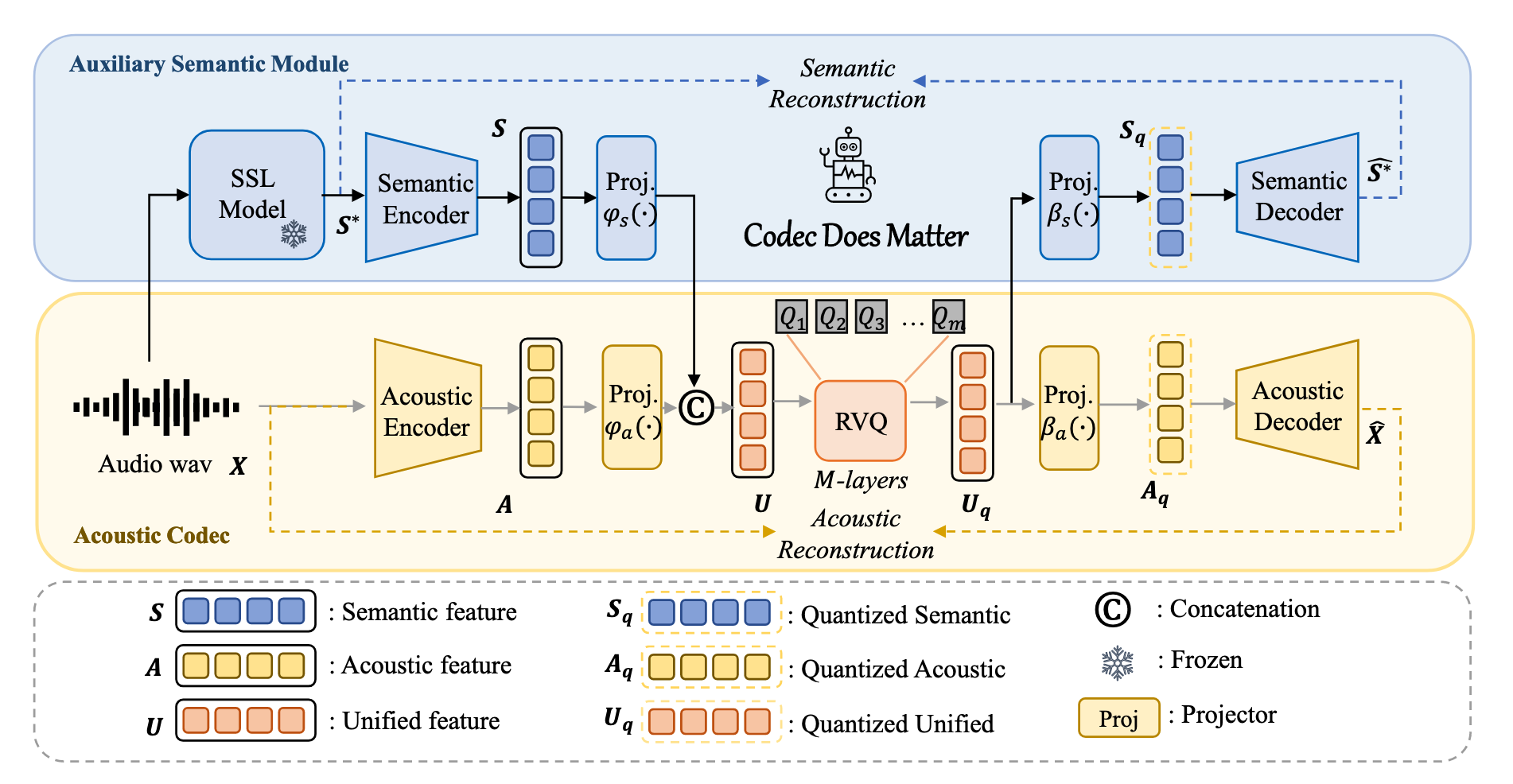
[24.08] X-Codec #
X-Codec 处理的问题是 AudioLLM 生成的内容常常是错的. 听起来很像人声但却是无意义的词语. 这是因为它们用的 codec 是为压缩音频而不是理解语义设计的.
核心的思想是将声学表征与语义信息做一个表征融合从而训练一个两者均有的 codec.
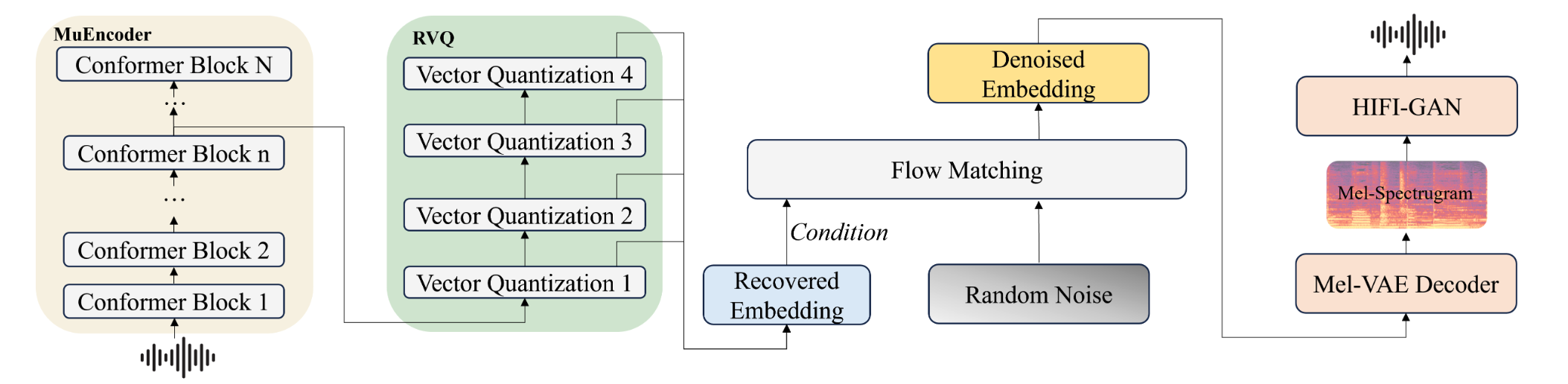
[24.09] MuCodec #
MuCodec 的目的是解决在极低码率下如何还原高质量音乐.
音乐与语音有一个核心的区别, 就是音乐包含人声+背景音. 需要同时建模语义+声学信息才能做到良好的压缩.
主要的创新点:
- Encoder 采用一个两阶段的训练, 先用类似 BERT 的方式训练上下文建模, 再同时训练声学表征 (重建 Mel 谱) 与语义表征 (歌词识别).
- 在生成方式上使用 Flow Matching 与 DiT. 把 Flow matching 引入到了 Codec 重建任务.
- 预测内容不再是音频, 而是预测中间表征 (Mel-VAE latent).
混合连续表征 #
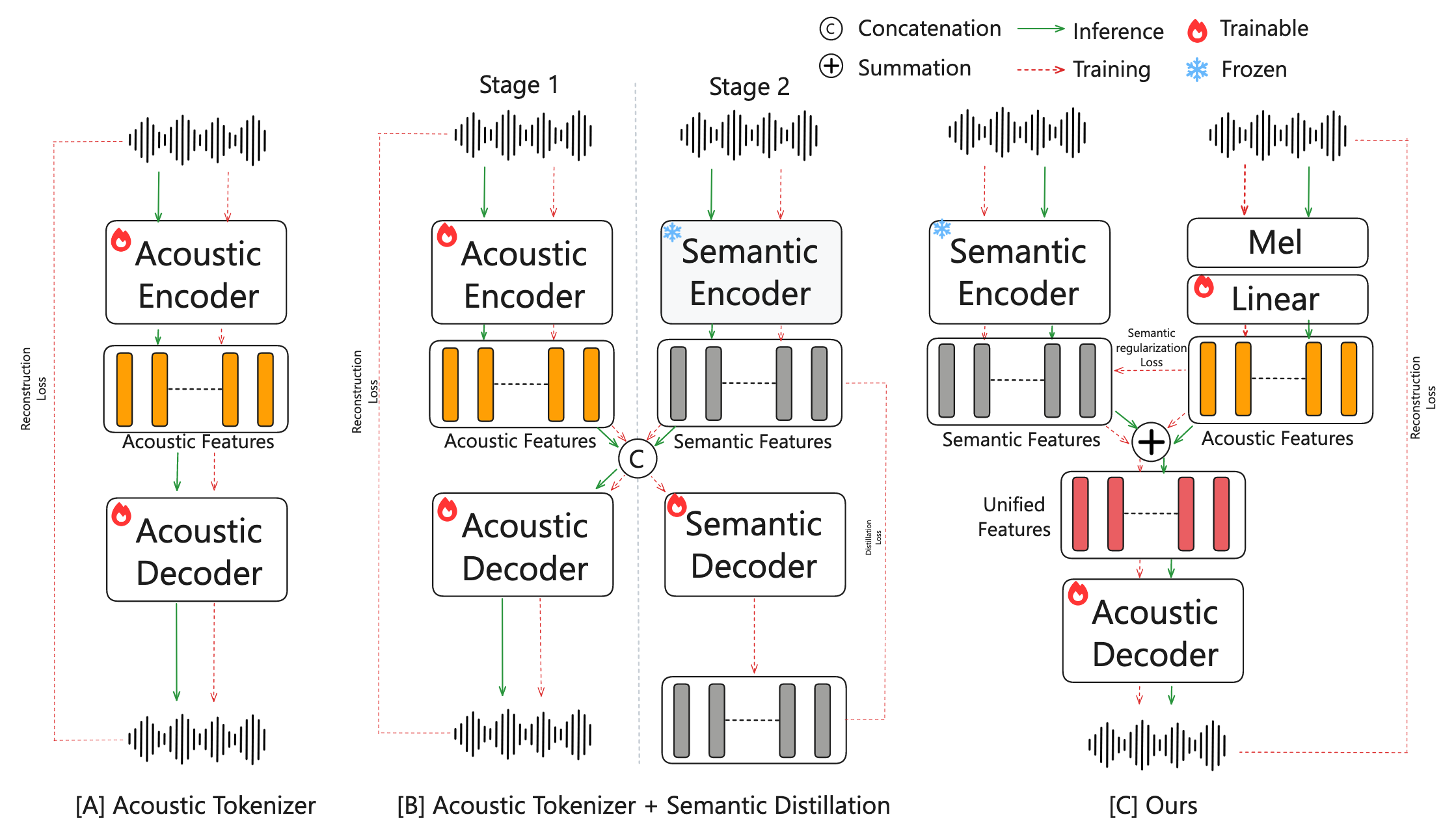
[26.02] DashengTokenizer #
这篇文章尝试用一个统一的音频表示, 同时做好理解和生成两件事.
核心的思路是冻结语义表征, 把声学表征注入到语义表征中.
为了防止声学表征破坏语义表征, 设计了一个语义保留损失: $\mathcal{L}_\text{sem} = ||z_\text{sem} - z_\text{ac}||_2^2$.
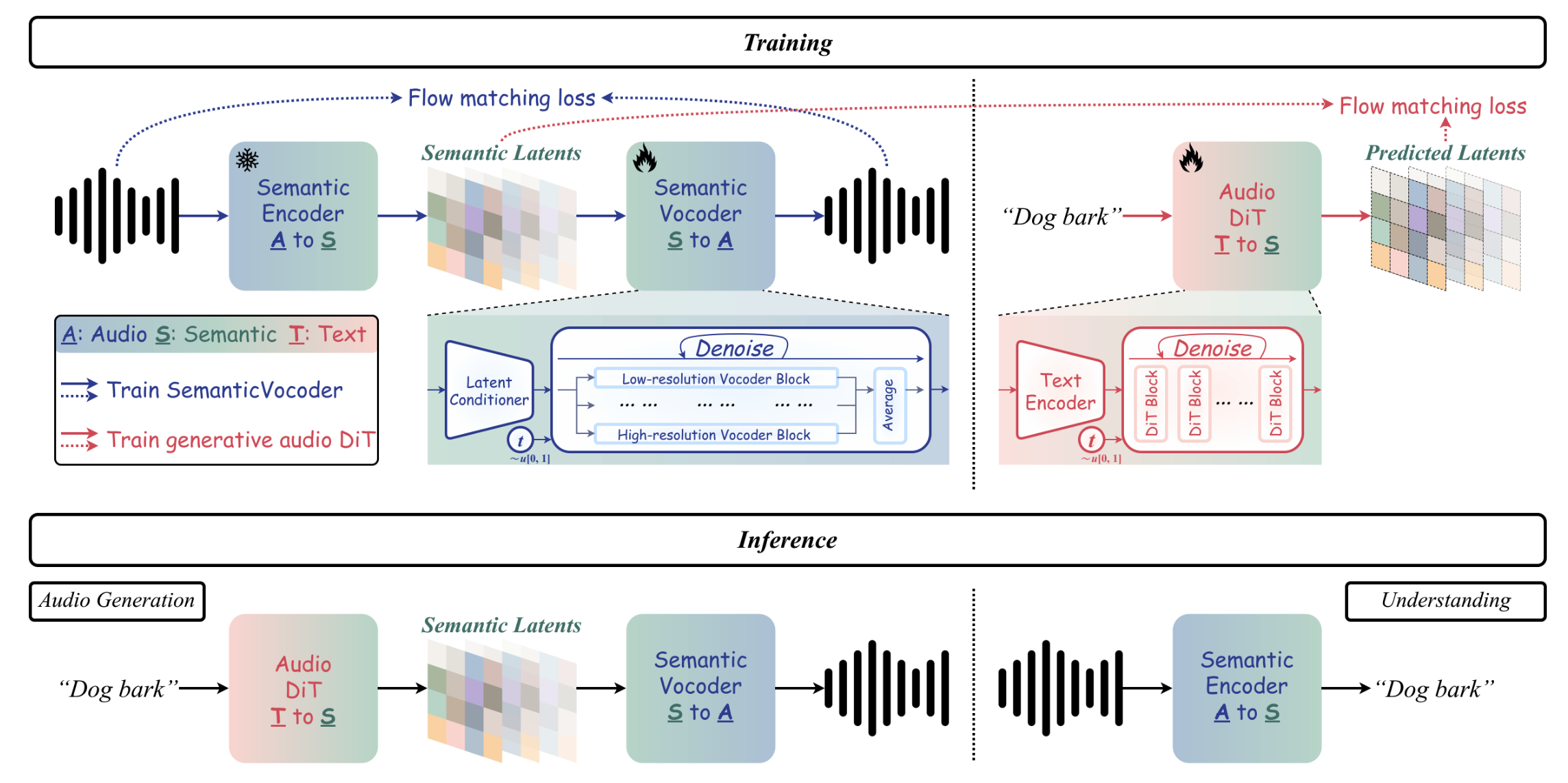
[26.02] SemanticVocoder #
这篇文章尝试用语义 latent 替代传统 VAE 的声学 latent, 直接生成音频. 从而把音频生成和理解统一到一个空间里. 有点 RAE 的感觉.
一些离散表征相关的论文 #
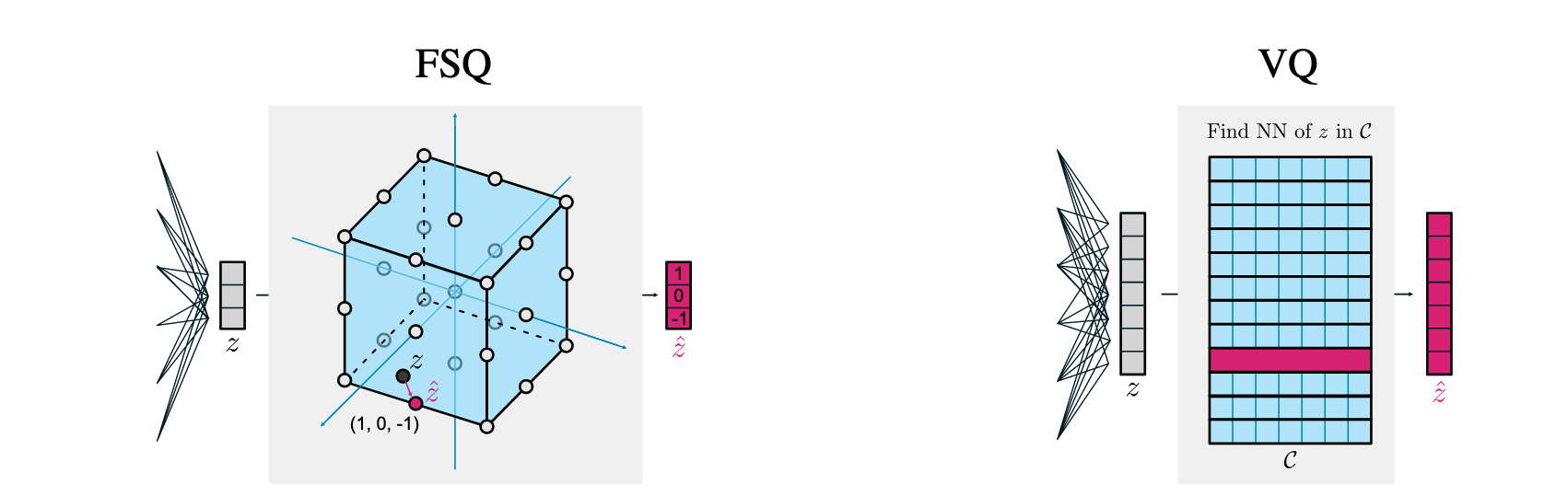
[23.09] FSQ #
FSQ 是 Google 提出的对 VQ-VAE 的改进.
核心的思路是用一个固定好的 codebook 而非学习出来的 codebook. 这样重建 loss 会强迫 encoder 使用更多格子.
假设 codebook 的维度是 $d$, 每维度的取值有 $L$ 个, 那么 codebook 的大小就是 $|C|=L^d$.
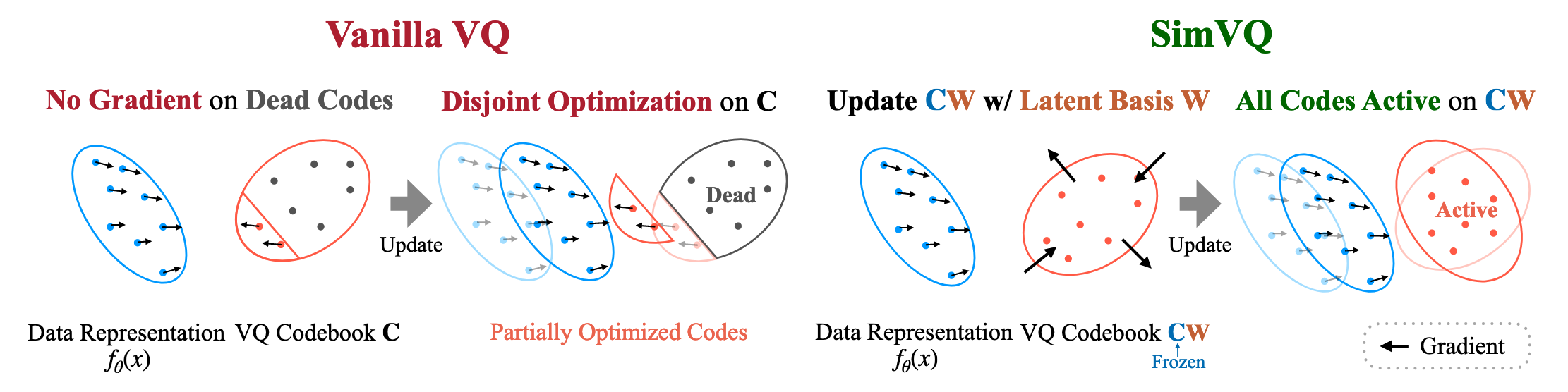
[24.11] SimVQ #
论文解决的问题是普通的 VQ 会有码本坍缩的问题.
关键的原因是优化是分离的. 由于每次更新都只更新选中的 code, 因此会导致越来越集中于几个 code.
论文给的解决方法也很简单: 加一个线性层. 将原本的 codebook:
$$C\in \mathbb R^{K\times d}$$改为
$$CW, W\in\mathbb R^{d\times d}$$也就是每个 code = 原始 code * 一个可学习的线性变换.
码本 $C$ 不再训练. 只训练 $W$.
音频自回归大模型 #
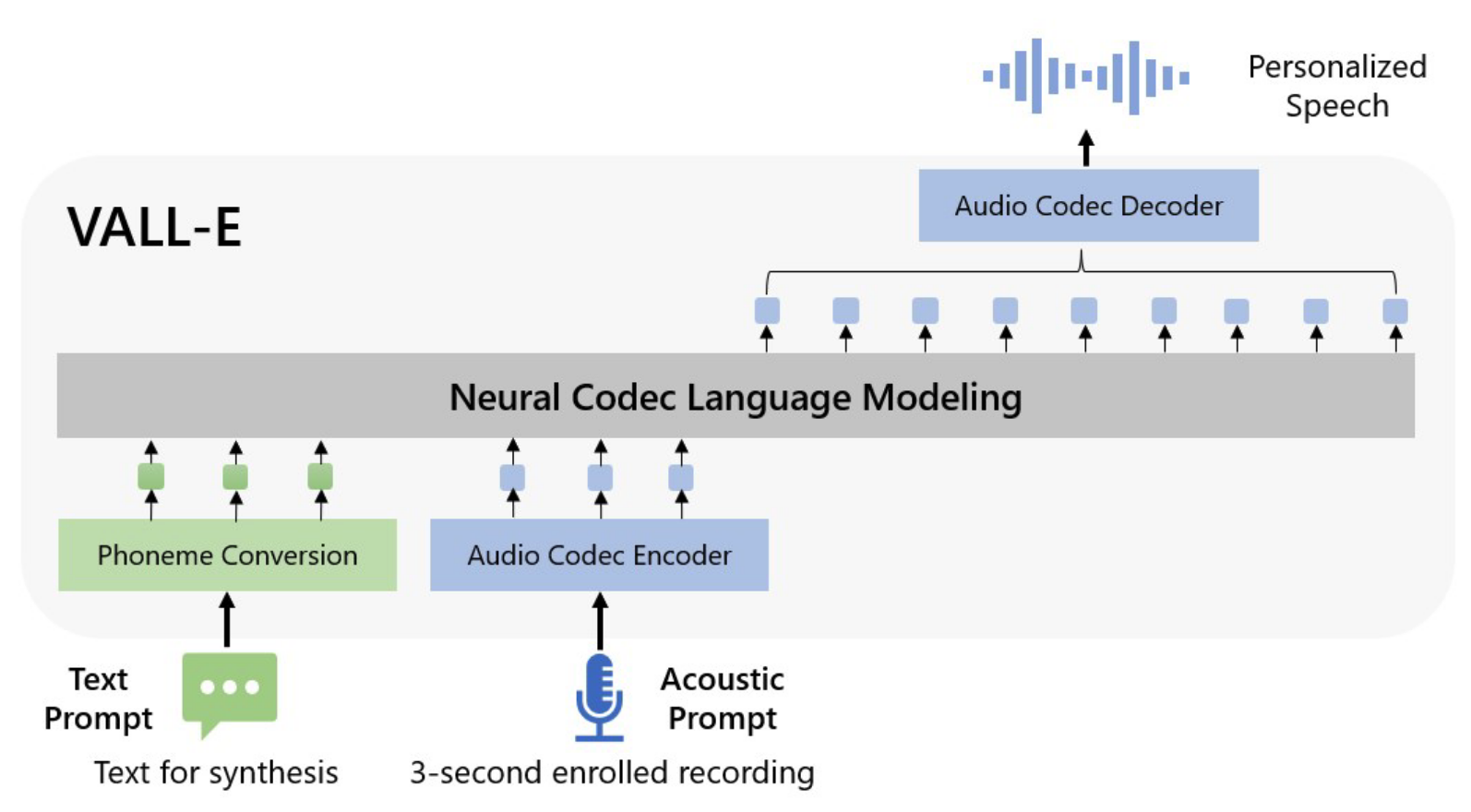
[23.01] VALL-E #
这篇文章用类似 GPT 的语言模型, 直接生成语音的离散 token, 实现 零样本语音克隆 (zero-shot TTS).
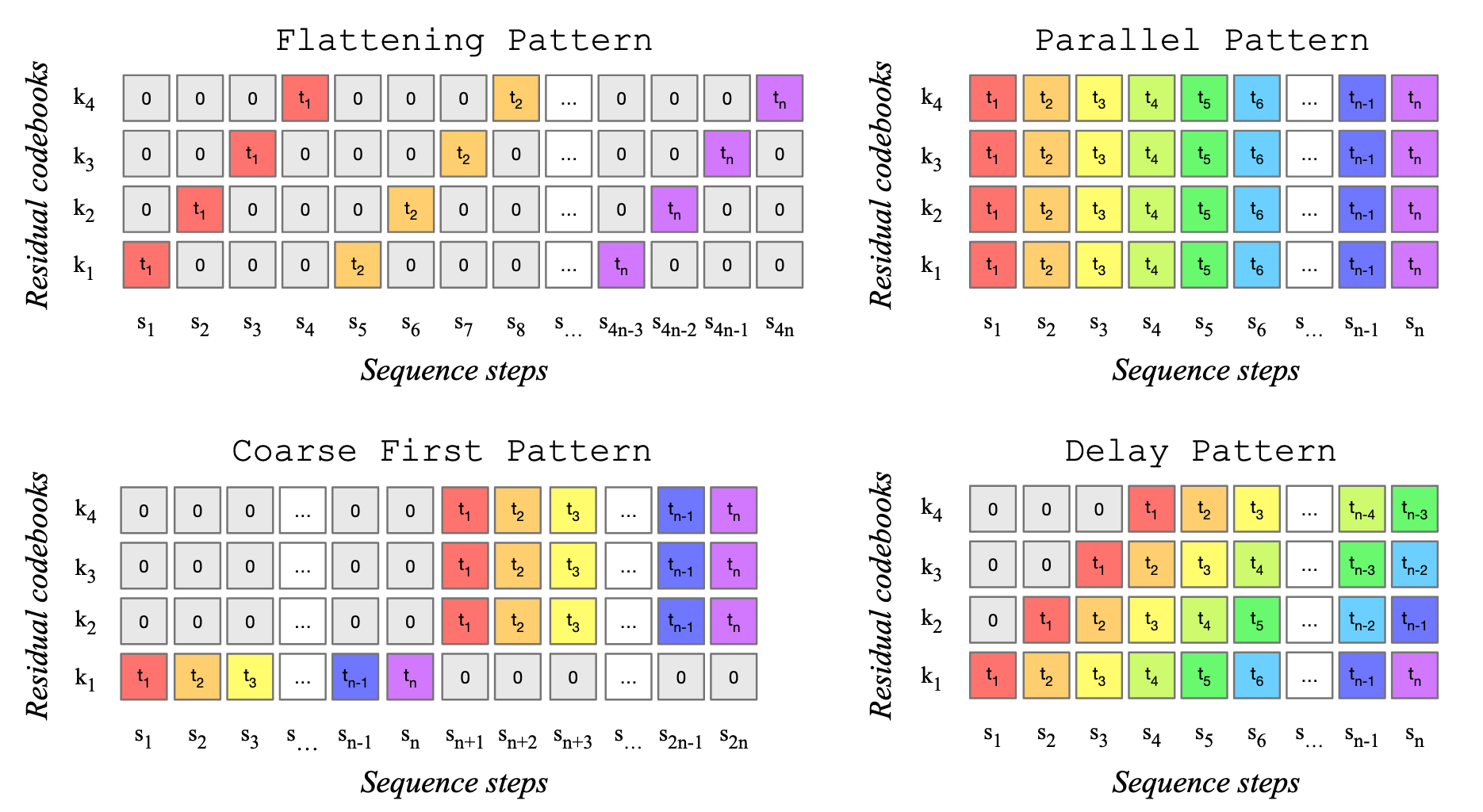
[23.06] MusicGen #
这个论文最核心的一点是讨论了 RVQ 之后多个 code 如何聚合成输入给 transformer 的序列.
下图展示了测试的四种组合方式. 横轴代表最终输入 transformer 的序列. 每一列求和得到最终序列中该位置的值. 论文测试得出的结论是 delay 排列是最好的.
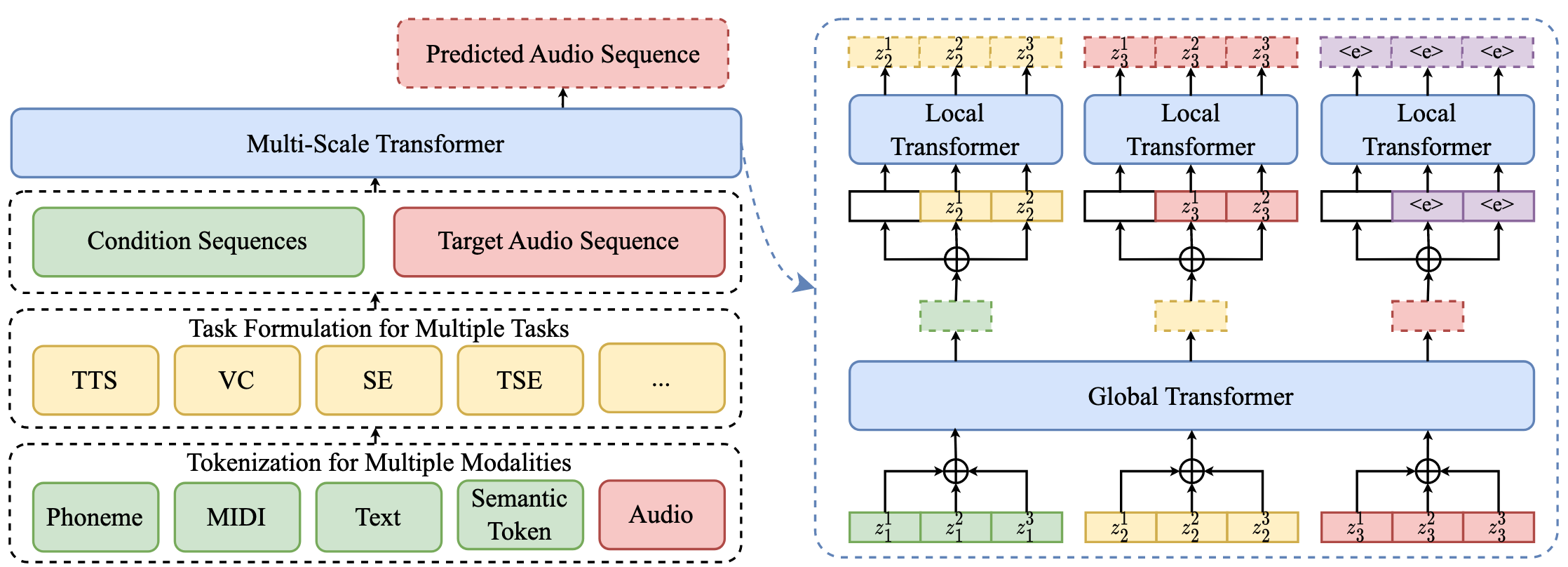
[23.10] UniAudio #
这篇论文尝试做一个音频界的 GPT, 一个模型搞定所有音频生成任务.
核心的贡献是 Multi-scale Transformer. 做了一个全局+局部的双层结构. 全局的负责语义, 局部的负责声学.
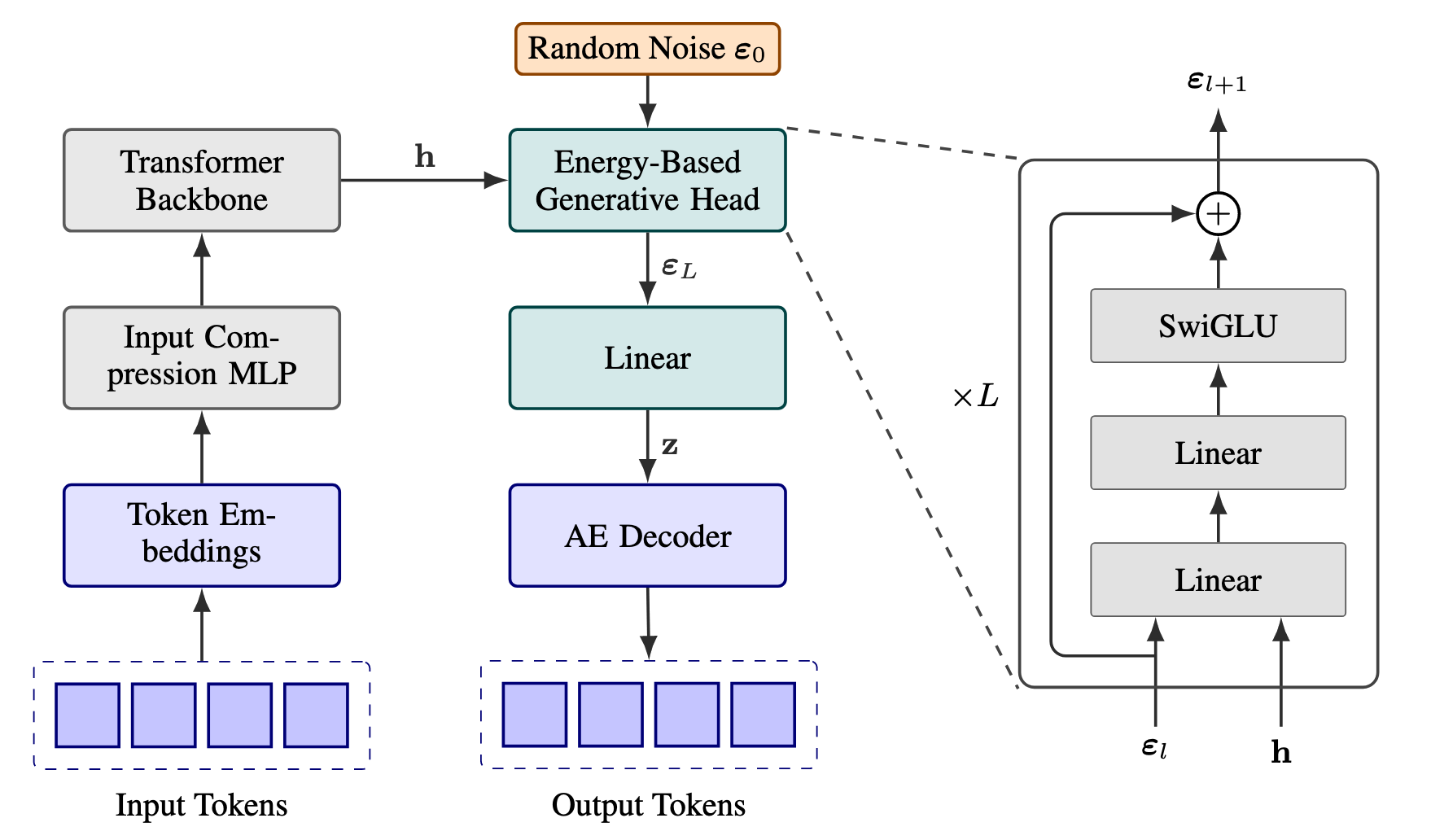
[25.10] CALM #
论文首先提出了一个思想: 用一个向量表示多个 Token 来压缩序列长度.
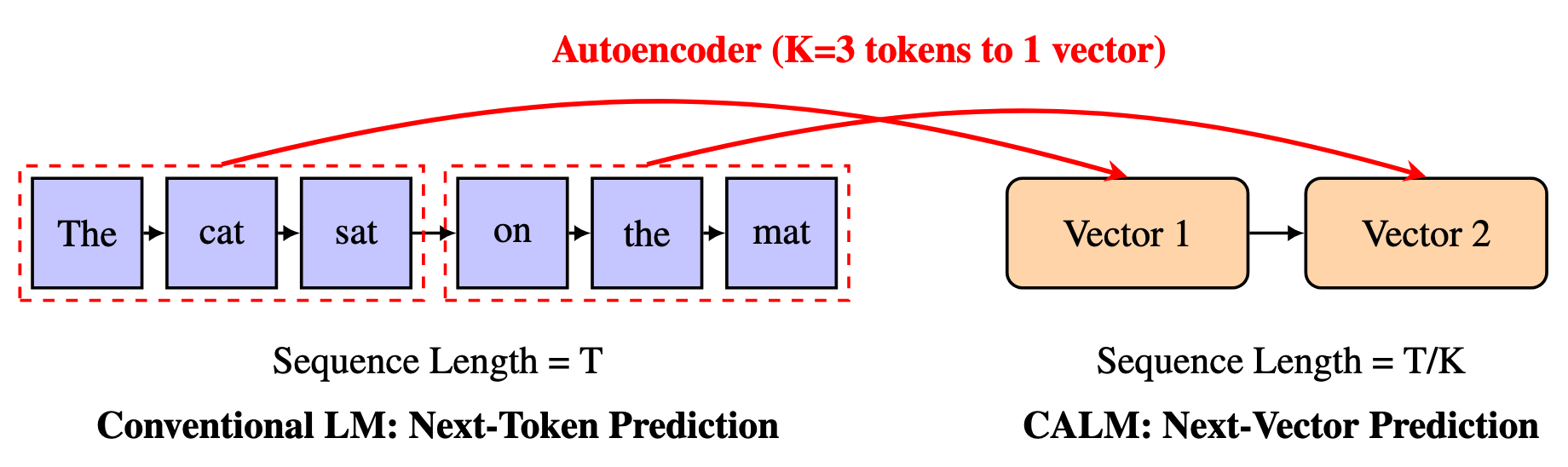
但这样的话如何训练呢?
论文提了个 Energy Transformer 出来. 其实是将 transformer 的隐藏层作为条件将一个随机噪声变成符合分布的向量, 从而 decode 成最终的 token.
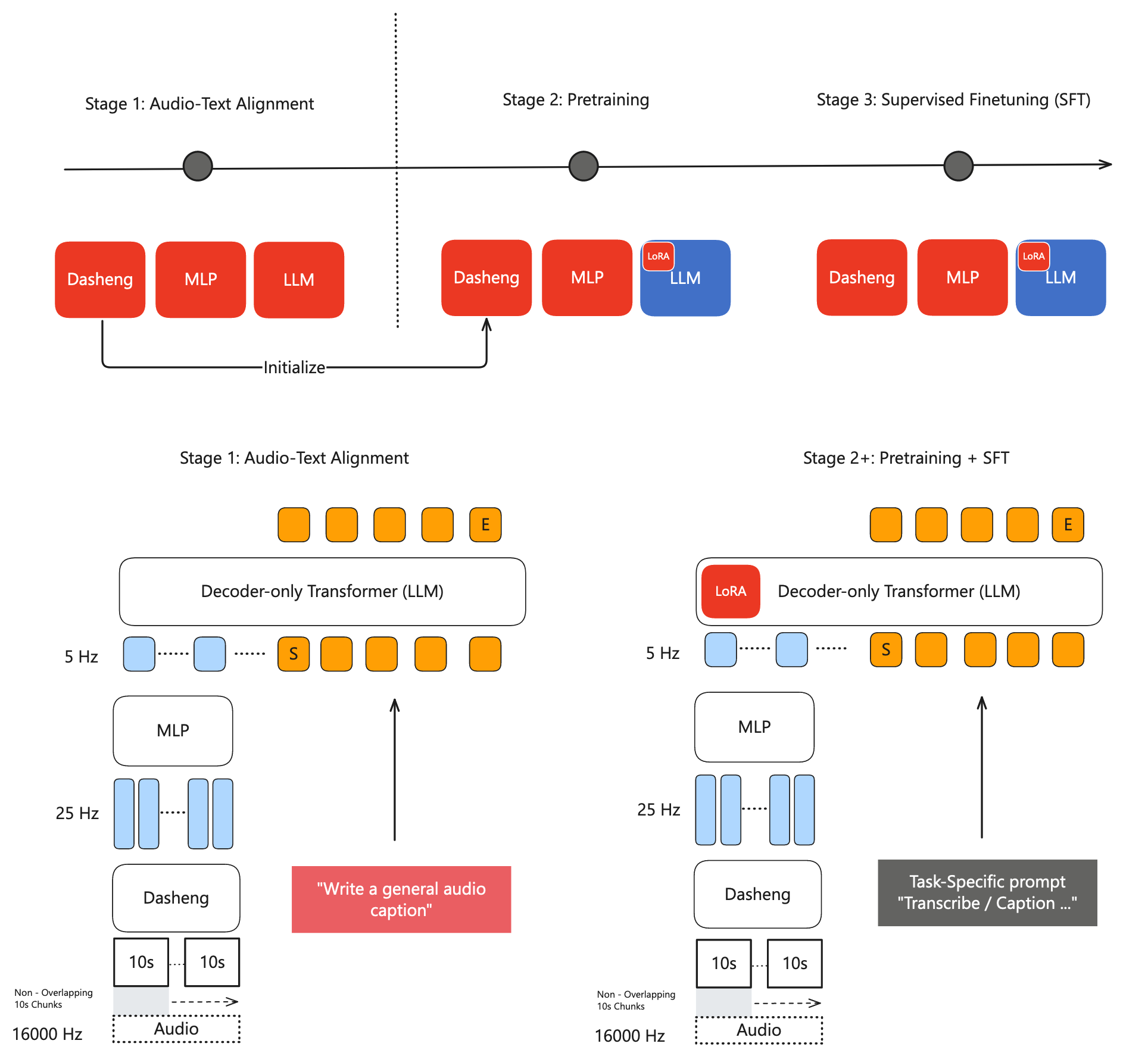
[25.08] MiDashengLM #
MiDashengLM 则是基于 Dasheng 做的一个 LALM. 它聚焦的一个点是常规的 LALM 过于重视 ASR 数据而非环境音等更宽泛的数据. 具体的创新点是:
- 将对齐目标从 ASR 转为一般的 caption. 并极大的扩充 music 与 sound.
- 原来的 ASR:
audio → "I went to the store yesterday" - 一般的 caption:
audio → "A male speaker calmly describes going shopping..." - 这样更强调语义理解.
- 原来的 ASR:
- 采用了分阶段训练, 先训练 caption 将 encoder 与 LLM 对齐, 再训练下游任务.
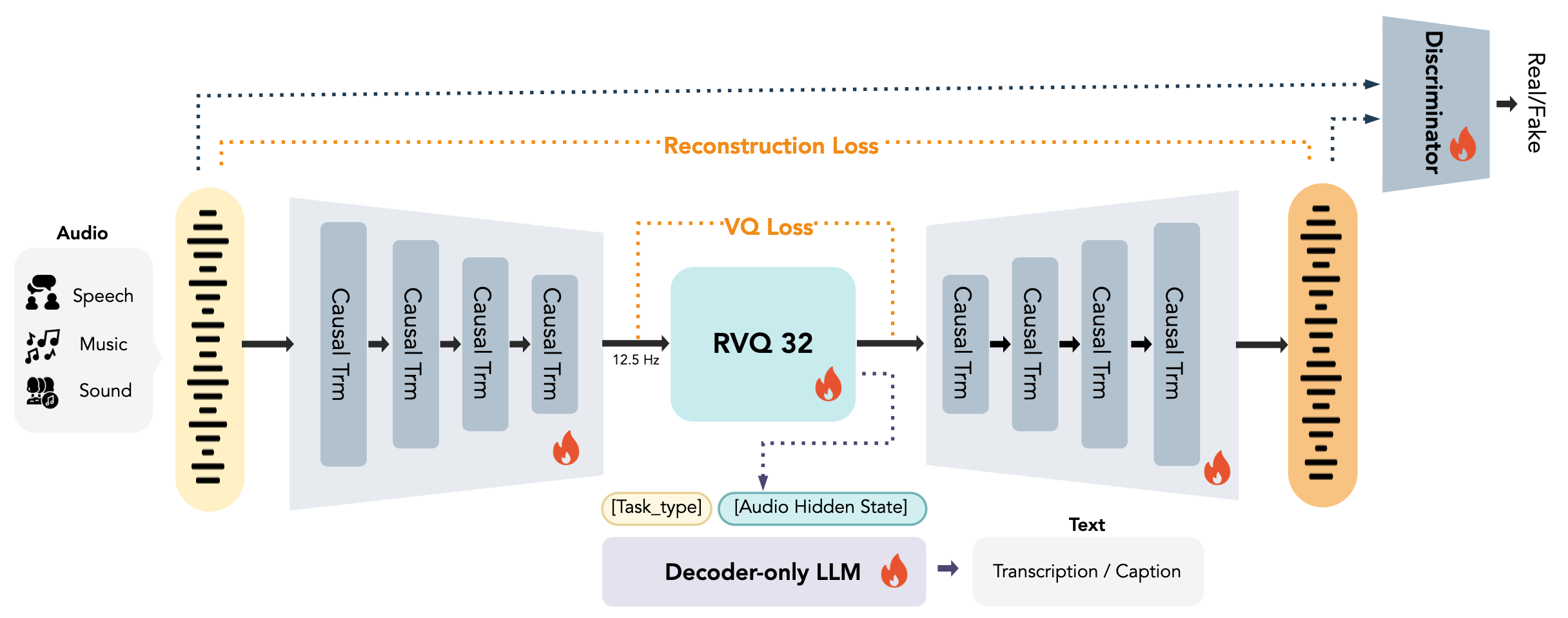
[26.02] MOSS-Audio-Tokenizer #
这篇文章的思路是像 LLM 一样训练 Audio Tokenizer: 纯 Transformer + 端到端训练 + 可扩展.