

本文为北大未名超算队高性能计算入门讲座(三)笔记。讲座录屏地址
Open MPI 入门笔记 #
什么是 MPI? #
消息传递接口( Message Passing Interface,缩写 MPI )是一个并行计算的应用程序接口(API),常在超级电脑、电脑集群等非共享内存环境程序设计。
MPI 是一个跨语言的通讯协议,用于编写并行计算机。支持点对点和广播。MPI 是一个信息传递应用程序接口,包括协议和和语义说明,他们指明其如何在各种实现中发挥其特性。MPI的目标是高性能,大规模性,和可移植性。MPI 在今天仍为高性能计算的主要模型。
MPI 可以大概分为两大类:Open MPI 和 MPICH 及其衍生。
MPICH 实现的比较全面,但是不支持 InfiniBand 这种比较新的硬件和协议。但是它的衍生品例如 Intel MPI 和 MVAPICH 支持比较新的硬件与协议。
Open MPI 也实现了 MPI 标准,并且应用广泛。它的进程管理比 MPICH 相对比较好。
Open MPI 与 OpenMP 是不同的概念。
Open MPI 的设计架构 #
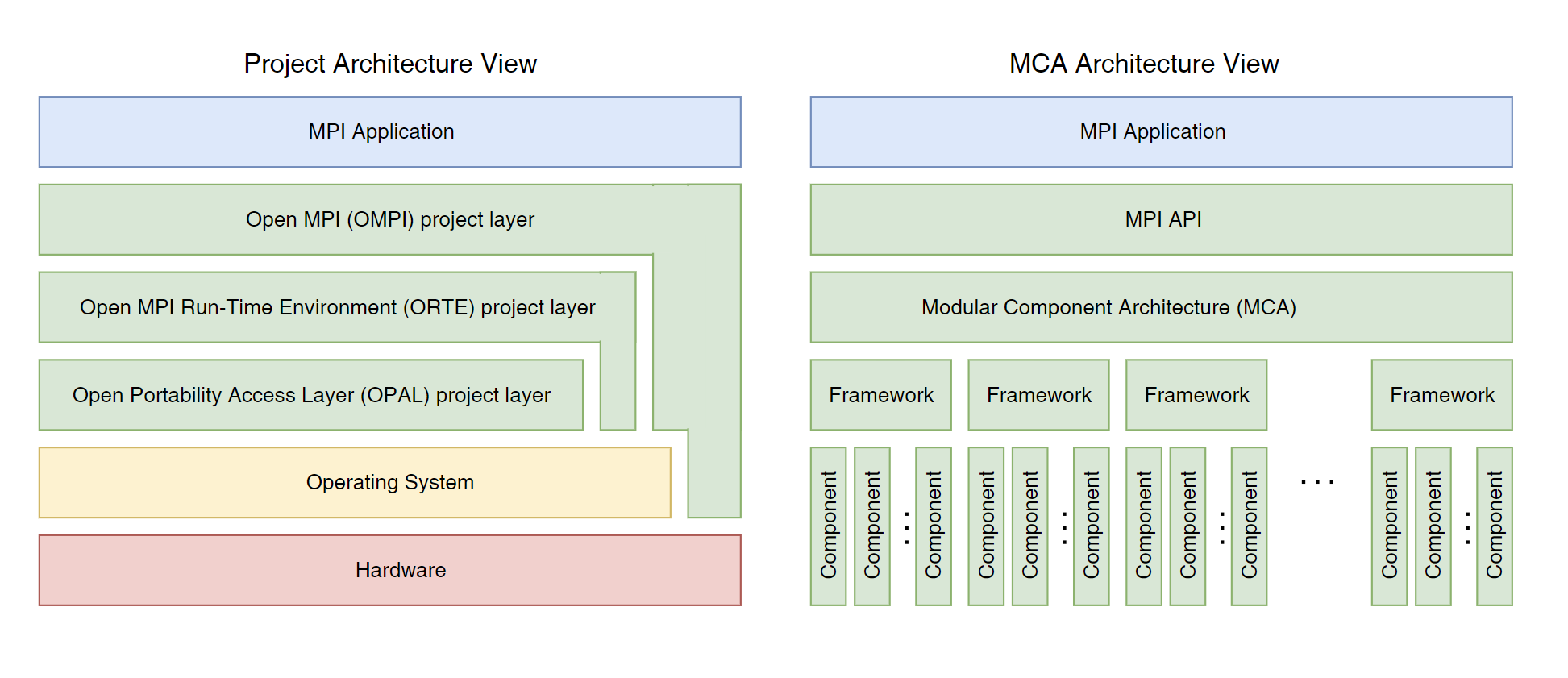
Open MPI 架构如左图所示,主要包括 OMPI, ORTE, OPAL 三层。 OMPI 包括公共的 MPI API 以及后端 MPI 语义以及逻辑。ORTE 不包括 MPI,是一个运行时系统。OPAL 则是 OS 级别的函数调用。
MCA 架构如右图所示。MCA 使得它可以支持一些更灵活的东西。Framework 类似于接口,而 Component 是 Framework 的实现,一般来说有硬件的制造商来实现。
Open MPI 的 Hello, world #
Code
#include <stdio.h>
#include <mpi.h>
int main(int argc, char *argv[]) {
MPI_Init(NULL, NULL);
int world_rank;
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank);
int world_size;
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
printf("Process %d of %d: Hello, world!\n", world_rank, world_size);
MPI_Finalize();
}
在这段代码里,有几句比较重要:
MPI_Init(NULL, NULL)在这一句之前,所有的进程都是完全相互独立的。MPI_COMM_WORLD是预定义好的通信器 (Communicator),通信器是一个包含了进程的集合,同一个通信器里面的进程可以相互通信。MPI_Comm_rank(MPI_COMM_WORLD, &world_rank)获取每个进程的在通信器里面的 Rank,也就是编号MPI_Finalize()这一句释放掉所有被 MPI 占用的资源。
Compile & Run
mpicc -o hello hello.c
mpirun -np 4 ./hello
Result
Process 0 of 4: Hello, world!
Process 2 of 4: Hello, world!
Process 3 of 4: Hello, world!
Process 1 of 4: Hello, world!
这里我们是无法控制输出的顺序的。
MPI 的主要思想是 SPMD (Single Program Multiple Data).
杂项 #
为什么 MPI 创建代价昂贵的进程而不是线程? #
这是为了保证跨节点的一致性。进程在执行过程中拥有独立的内存单元,而多个线程共享内存。可以使用混合的方式实现一个节点部署一个多线程 MPI 进程(使用 OpenMP 和 CUDA)。
为什么使用 MPICC 编译而不是用 GCC? #
实际上 MPICC 的后端还是 GCC。MPICC 只是添加了动态链接库。
点对点通信 (Point to Point) #
接收与发送 #
MPI_Send用来发送信息MPI_Recv用来接收信息
int MPI_Send(void *buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm);
int MPI_Recv(void *buf, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Status *status);
参数说明
buf内存地址,用于接收/发送消息的存储。count传送消息的数量datatype传输数据类型,除了 C 自带的类型以外,MPI 还定义了一些类型dest接收节点source发送节点tag信息的标签comm通信器status接收消息的状态
传递信息可以看作是一个 Message Envelope.
值得一提的是,接收消息的长度跟发送消息的长度是可以不同的,但是最好保证接收消息的长度 大于等于 发送的长度,以免溢出。
简单的例子:Ping-Pong #
Code
#include <stdio.h>
#include <mpi.h>
#include <stdlib.h>
int main(int argc, char *argv[]) {
MPI_Init(&argc, &argv);
int numP, myId;
MPI_Comm_rank(MPI_COMM_WORLD, &myId);
MPI_Comm_size(MPI_COMM_WORLD, &numP);
if(numP % 2 != 0) {
if(!myId) {
printf("ERROR: the number of ping-pong processors must be even number!\n");
}
MPI_Abort(MPI_COMM_WORLD, EXIT_FAILURE);
}
int partner_id;
int odd = myId & 1;
if(odd) {
partner_id = myId - 1;
} else {
partner_id = myId + 1;
}
int a, b;
if(odd == 0) {
a = -1;
printf("Process %d sends token %d to process %d\n", myId, a, partner_id);
MPI_Send(&a, 1, MPI_INT, partner_id, 0, MPI_COMM_WORLD);
MPI_Recv(&b, 1, MPI_INT, partner_id, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
printf("Process %d receives token %d from process %d\n", myId, b, partner_id);
} else {
a = 1;
MPI_Recv(&b, 1, MPI_INT, partner_id, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
printf("Process %d receives token %d from process %d\n", myId, b, partner_id);
printf("Process %d sends token %d to process %d\n", myId, a, partner_id);
MPI_Send(&a, 1, MPI_INT, partner_id, 0, MPI_COMM_WORLD);
}
MPI_Finalize();
}
Result
Process 2 sends token -1 to process 3
Process 0 sends token -1 to process 1
Process 1 receives token -1 from process 0
Process 1 sends token 1 to process 0
Process 0 receives token 1 from process 1
Process 3 receives token -l from process 2
Process 3 sends token 1 to process 2
Process 2 receives token 1 from process 3
死锁 #
每个 Send 要确保有对应的 Recv。除此以外,还要注意死锁问题,每个 Recv 都能即使获取到发送的东西。
阻塞通信与非阻塞通信 #
刚才说的是阻塞通信,在发送出去/接收到之前,程序会停止运行。相对的,也存在非阻塞通信。如下:
MPI_ISend用来发送信息MPI_IRecv用来接收信息
int MPI_ISend(void *buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm, MPI_Request *request);
int MPI_IRecv(void *buf, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Request *request);
request 用于标记通信任务。在使用非阻塞通信传来的数据之前,需要使用 MPI_Wait 确认是否数据已经传入缓冲区。
非阻塞通信还有如下的控制与测试函数:
MPI_Cancel用于取消非阻塞通信。MPI_Test用于测试非阻塞通信是否已经结束。MPI_Wait用于等待非阻塞通信数据。
简单的例子:环形 Ping-Pong #
跟之前的例子不同,如果我们进行环形的 Ping-Pong 通信,就会产生死锁问题。我们无法确定谁应该先接收,谁应该后接受。所以使用非阻塞通信实现。
Code
#include <stdio.h>
#include <mpi.h>
#include <stdlib.h>
int main(int argc, char *argv[]) {
MPI_Init(&argc, &argv);
int numP, myId;
MPI_Comm_rank(MPI_COMM_WORLD, &myId);
MPI_Comm_size(MPI_COMM_WORLD, &numP);
int next_id = (myId + 1) % numP, prev_id = (myId - 1 + numP) % numP;
MPI_Request rq_send, rq_recv;
int a = 1, b;
MPI_Isend(&a, 1, MPI_INT, next_id, 0, MPI_COMM_WORLD, &rq_send);
MPI_Irecv(&b, 1, MPI_INT, prev_id, 0, MPI_COMM_WORLD, &rq_recv);
MPI_Wait(&rq_recv, MPI_STATUS_IGNORE);
printf("%d receive token %d from %d\n", myId, b, prev_id);
MPI_Barrier(MPI_COMM_WORLD);
a = -1;
MPI_Isend(&a, 1, MPI_INT, prev_id, 0, MPI_COMM_WORLD, &rq_send);
MPI_Irecv(&b, 1, MPI_INT, next_id, 0, MPI_COMM_WORLD, &rq_recv);
MPI_Wait(&rq_recv, MPI_STATUS_IGNORE);
printf("%d receive token %d from %d\n", myId, b, next_id);
MPI_Barrier(MPI_COMM_WORLD);
MPI_Finalize();
}
Result
5 receive token 1 from 4
6 receive token 1 from 5
4 receive token 1 from 3
1 receive token 1 from 0
0 receive token 1 from 6
2 receive token 1 from 1
3 receive token 1 from 2
1 receive token -1 from 2
4 receive token -1 from 5
0 receive token -1 from 1
6 receive token -1 from 0
5 receive token -1 from 6
3 receive token -1 from 4
2 receive token -1 from 3
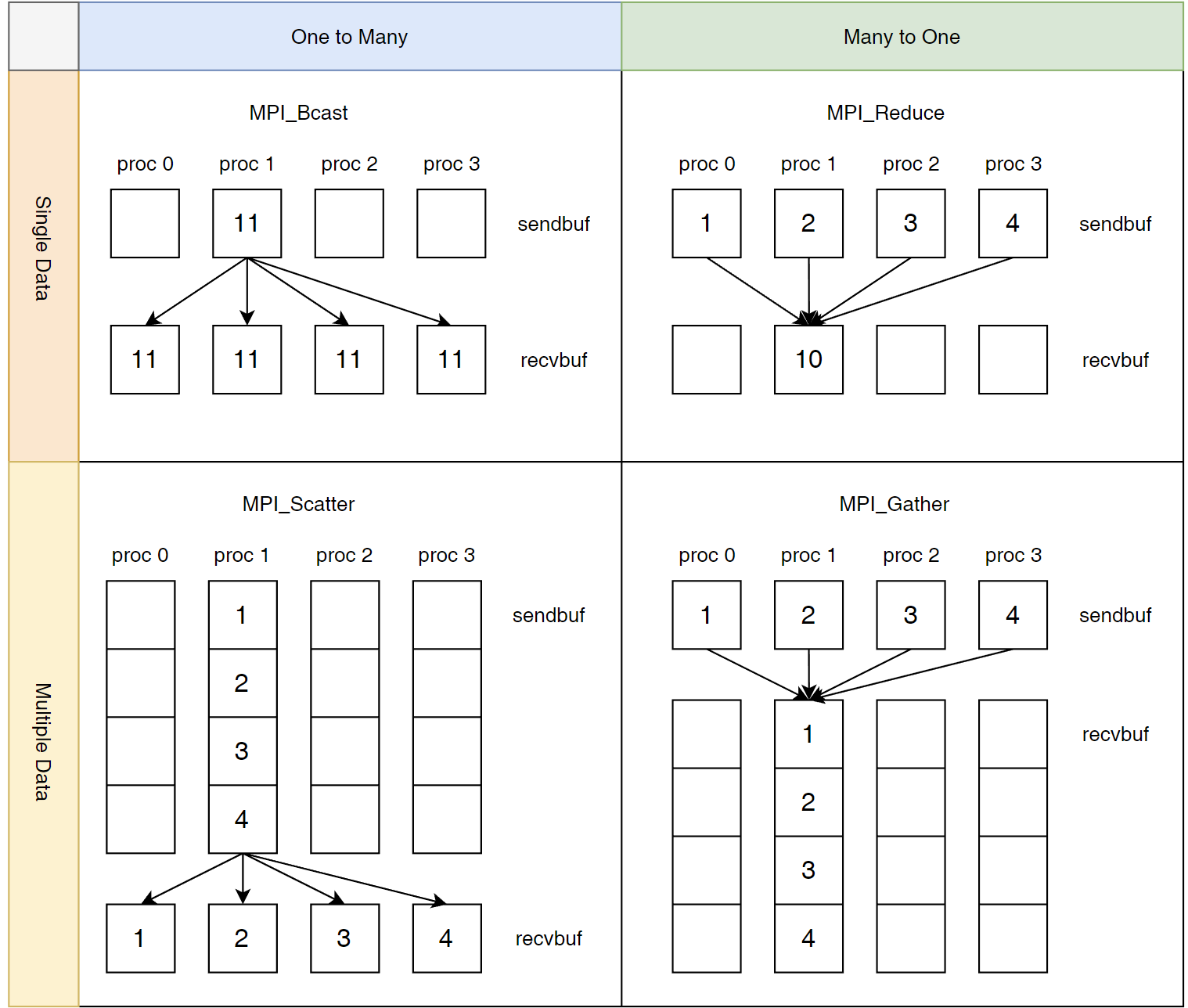
聚合通信 (Collective Communication) #
除了点对点通信之外,MPI 还有其他的通信方式如图所示。
简单的实例:计算质数数量 #
Code
#include <stdio.h>
#include <mpi.h>
#include <stdlib.h>
int main(int argc, char *argv[]) {
MPI_Init(&argc, &argv);
int numP, myId;
MPI_Comm_rank(MPI_COMM_WORLD, &myId);
MPI_Comm_size(MPI_COMM_WORLD, &numP);
int n = atoi(argv[1]);
MPI_Barrier(MPI_COMM_WORLD);
double start = MPI_Wtime();
int myCount = 0;
int total;
int prime;
for(int i = 2 + myId; i <= n; i += numP) {
prime = 1;
for(int j = 2; j < i; ++j) {
if(i % j == 0) {
prime = 0;
break;
}
}
myCount += prime;
}
MPI_Reduce(&myCount, &total, 1, MPI_INT, MPI_SUM, 0, MPI_COMM_WORLD);
double end = MPI_Wtime();
if(!myId) {
printf("%d primes between 1 and %d\n", total, n);
printf("Time with %d processes: %.3lf seconds\n", numP, end - start);
}
MPI_Finalize();
}
MPI_Reduce 中有预定义好的 MPI_Ops 例如 MPI_MAX, MPI_SUM 等等。
Result
mpirun -np 10 ./prime 100000
9592 primes between 1 and 100000
Time with 10 processes: 0.265 seconds
mpirun -np 1 ./prime 100000
9592 primes between 1 and 100000
Time with 1 processes: 1.012 seconds
根据 Amadhl 定律,所用时间并不会是原来的 1/10,而是会大一些。
更多高级特性 #
- 派生的数据类型
- 通信器切分
- 进程组
- …
小结 #
- MPI 是一个标准的定义,它提供了可移植的接口。它可以进行节点间通信。
- MPI 提供了一个启动器 (launcher) 实现跨节点启动多个进程。
- 有两种通信方式:点对点通信与聚合通信。
- 点对点通信方式可以分为:阻塞通信跟非阻塞通信。非阻塞操作可以避免死锁,并且实现通信与计算的并行。
- MPI 编程原则:最大化计算操作与通信操作的比例。
参考 #
- 杨超, 北京大学课程《并行与分布式计算基础》课件.
- Schmidt B, Gonzalez-Dominguez J, Hundt C, et al. Parallel programming: concepts and practice. Morgan Kaufmann, 2017.