

本文为北大未名超算队高性能计算入门讲座(二)笔记。讲座录屏地址
CUDA 入门笔记 #
为什么选择 GPU ? #
- 快
- 通用
- 软件环境
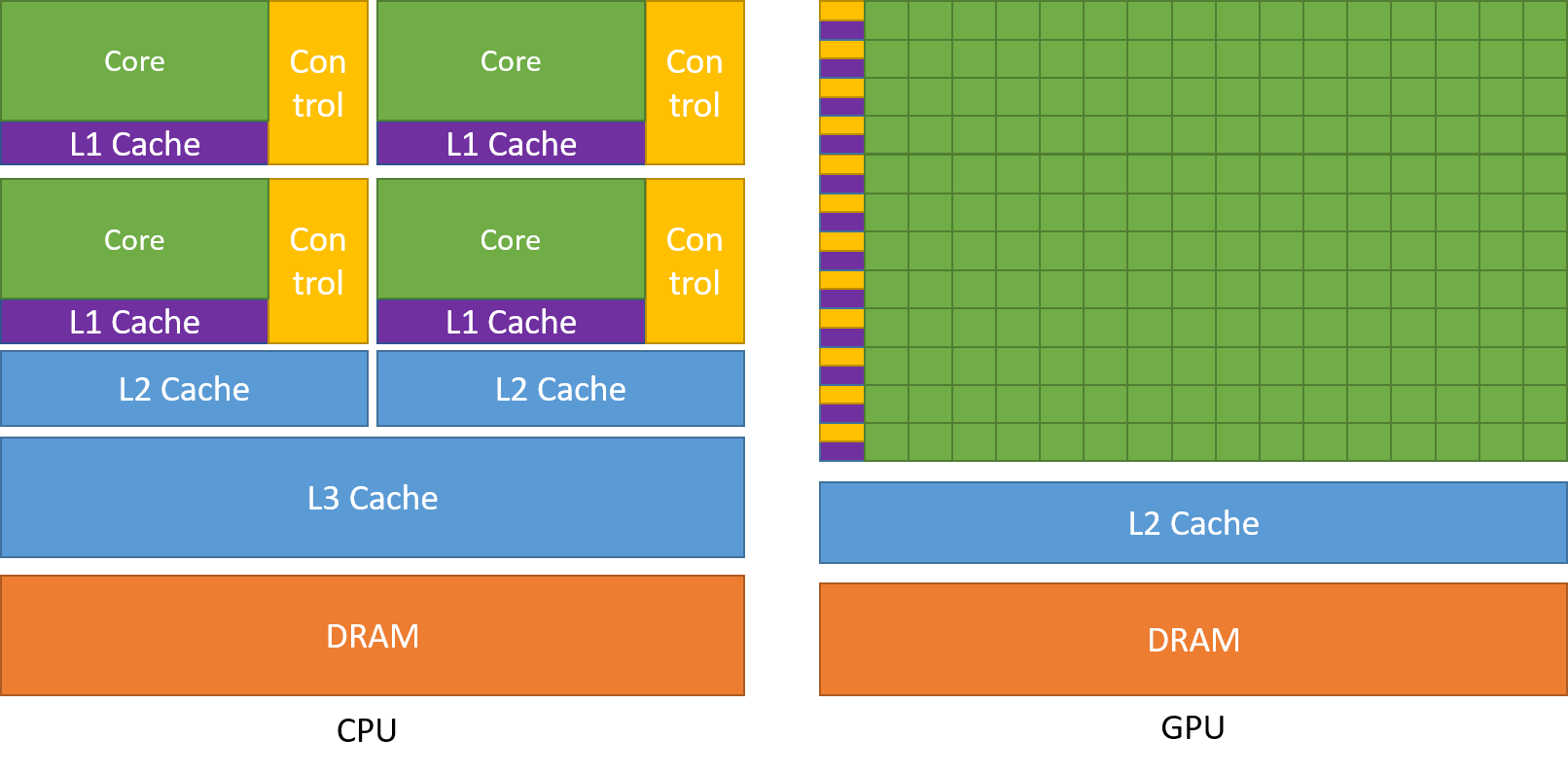
相较于 CPU 来说,GPU 核心数量更多一些,能够容纳的线程数更多一些。更加适合并行的计算。
CUDA 的 Problem a+b #
__global__ void vecAdd(double *a, double *b, double *c, int n) {
// Get our global thread ID
int id = blockIdx.x * blockDim.x + threadIdx.x;
// Make sure we do not go out of bounds
if(id < n)
c[id] = a[id] + b[id]
}
__global__ 意味着这是一个 CUDA kernel, 并且这个 kernel 是从 CPU 端调用,GPU 端执行。
除此以外还有:
__host__意味着 kernel 是从 CPU 端调用,CPU 端执行。__device__意味着 kernel 从 GPU 端调用,GPU 端执行。
int id = blockIdx.x * blockDim.x + threadIdx.x; 为每一个线程分配了一个 id,从而每个线程根据分配到的 id 进行工作。
对于一个向量相加,CPU 用时 24364 us 而 GPU 用时 293 us,可以看出 GPU 快了接近 100 倍。
为什么 GPU 会快这么多? #
实际上,在给 GPU 编程时,我们会给上千个 Core 分配上万个 Thread, 也就是说,一个 Core 上会有十来个 Thread. 每当有一个 Thread 的数据可用,那么对应的 Thread 就会被唤醒。
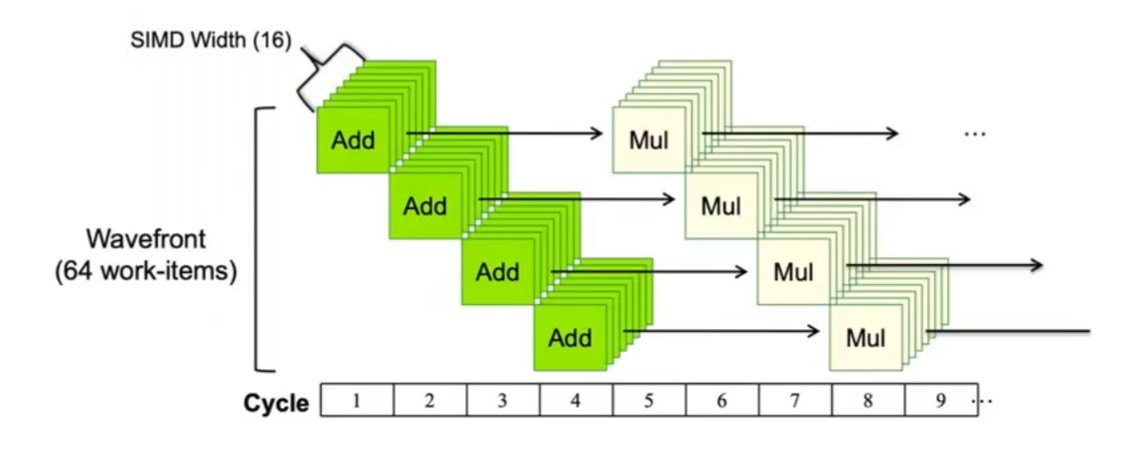
比如说上面这张图,假设 GPU 的调度器是以 16 个 Core 为单位,那么在 Cycle 1 时,调度器发现 Thread 0-15 的数据可用,就会一次性执行加法操作,在 Cycle 2 时又发现 Thread 16-31 的数据可用,那么就会一次性执行加法操作。以此类推。
简单来说,GPU 用并行掩盖了访存延迟,
CUDA 接口结构 #
CUDA 提供了一个层级化的接口,每一个 Kernel 对应一个 Grid。如图所示:
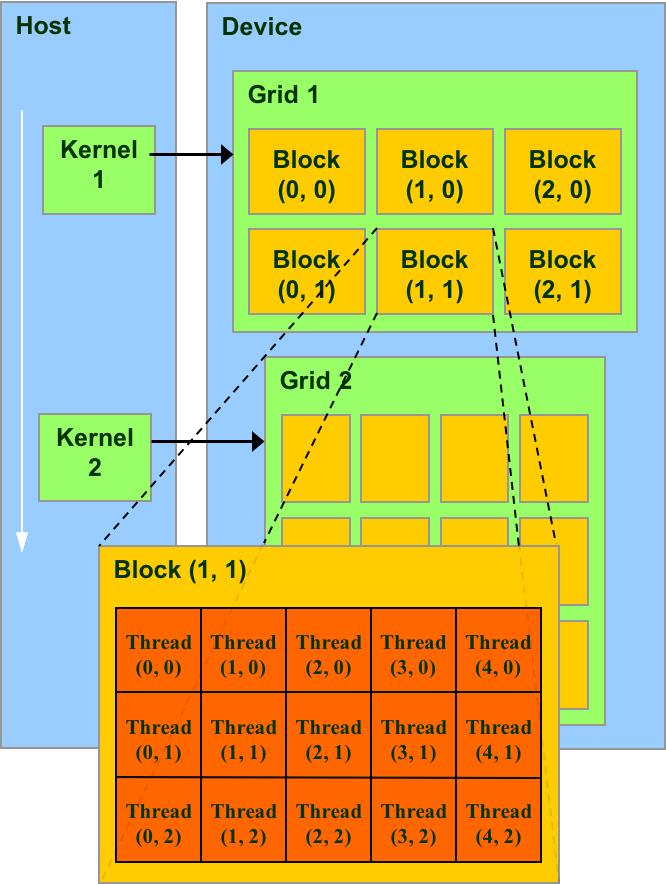
每一个 Grid 都有很多个 Block,Block 的编号可以是一维的或者多维的。图中的 Block 编号就是二维的。每个 Block 中又会有若干个 Thread. 同样的,Thread 的编号也可以是一维的或者多维的。
下面这张图就是一维的 Block 与 Thread。
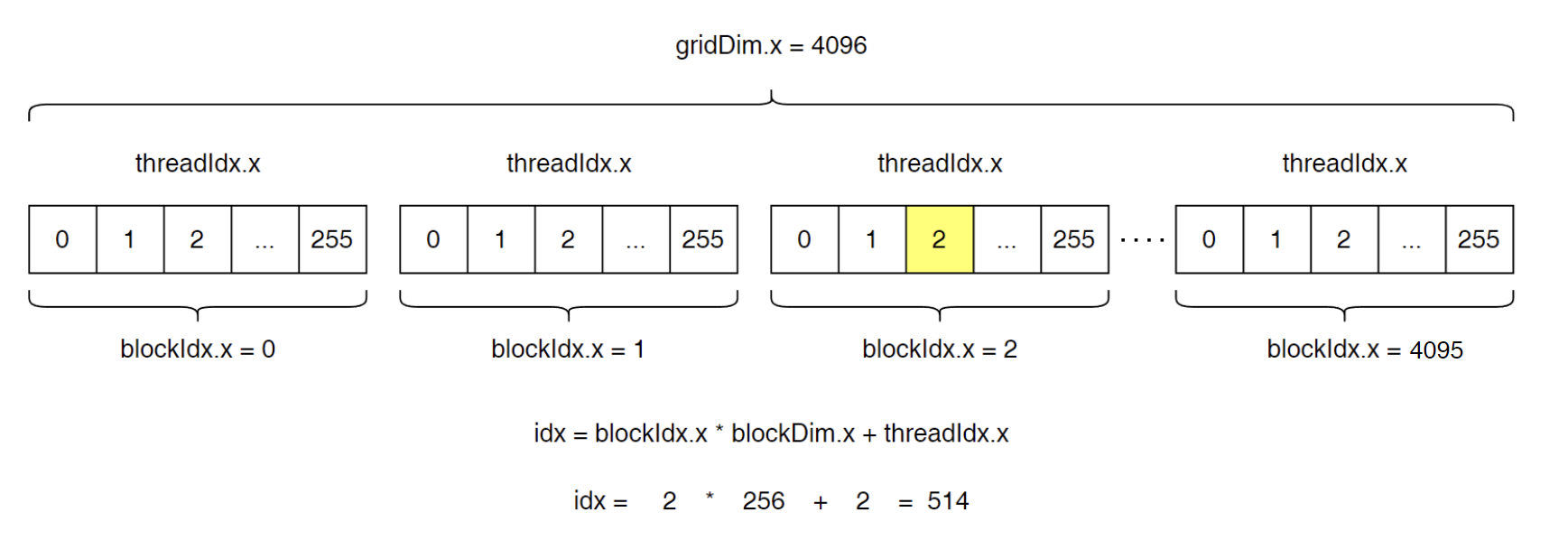
通过这张图,不难理解之前的 a+b 问题中的 int id = blockIdx.x * blockDim.x + threadIdx.x; 是如何得来的了。
值得一提的是,Block 与 Thread 都是并行执行的。单个 Kernel 只有一个 Grid.
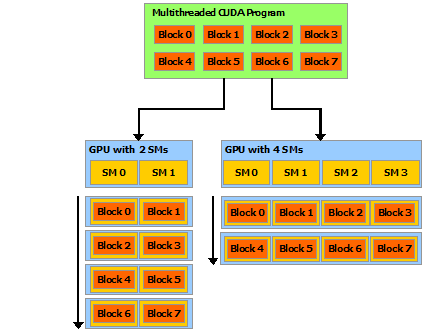
硬件上,Block 会映射到 SM(Streaming Multiprocessor) 上面,多个 Block 会映射到一个 SM 上。而在工作时,SM 会优先处理可用的 Block,比如说 Block 0 处理完毕后,对应的 SM 会去处理 Block 2,从而加速运算。而在每个 Block 里面,多个 Thread 也会映射到同一个 Core 上。
除此以外,CPU 的上下文切换需要弹栈重置寄存器,而 GPU 的寄存器数量决定了它能装载 Thread 的数量。 GPU 拥有大量的寄存器,这也使得它切换的速度非常快,从而掩盖访问的延迟问题。
CUDA 编程的 if…else 问题 #
GPU 作为 SIMT(Single Instruction Multiple Threads) 体系结构,在执行 if…else 语句时有时会产生意想不到的问题。
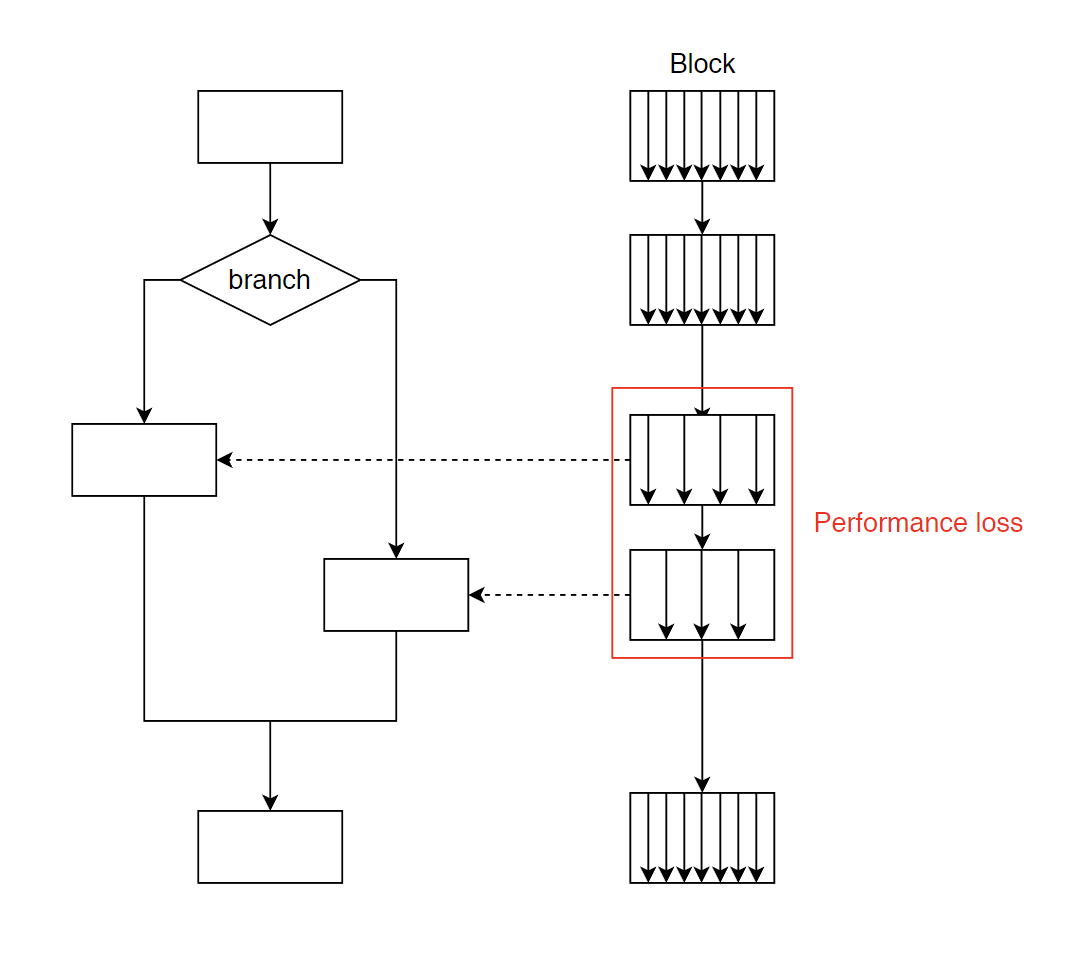
如上图所示,GPU 在执行 if…else 分支时,由于 if 与 else 分支的指令不同,所以必须分两次执行 if 与 else,也就是说变成了串行结构,在这种情况下,总的延迟=if分支延迟+else分支延迟+判断延迟。因此,一般来说,应当尽量减少 if…else 的使用。
但是,有两种情况除外:
一种是三目运算符:(condition) ? a : b 编译器可以将三目运算符编译成为一条 SIMT 指令,从而减少速度的损耗。
另一种是仅 if 分支,同样的,编译器也对此进行了优化。
而普通的 if…else 分支,在 Volta 架构之后进行了优化,但是效果并不明显,因此要尽量减少使用。
CPU 与 GPU 的通信 #
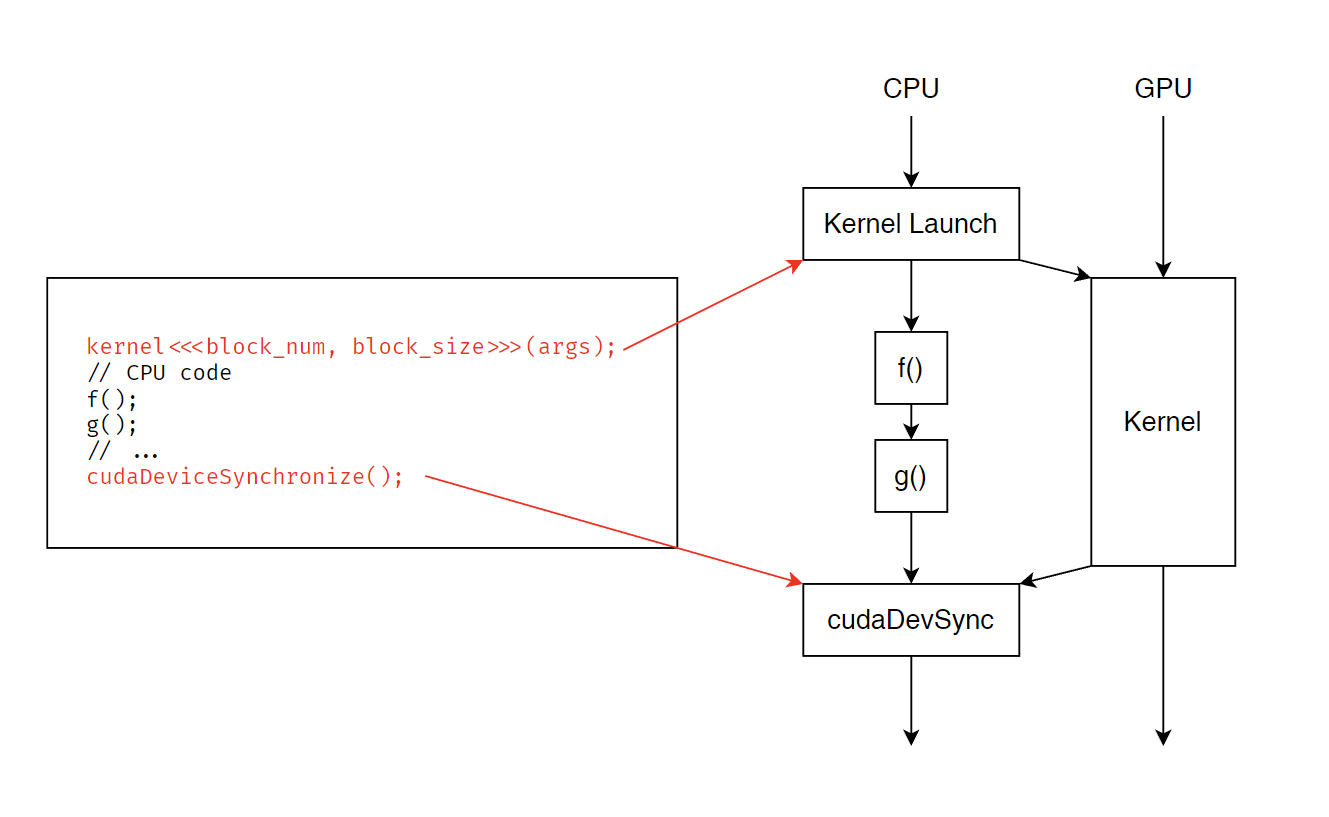
如图,GPU 上面启动 Kernel 不会妨碍 CPU 指令的运行。在执行完 CPU 部分等待 GPU 时,需要调用 cudaDeviceSynchronize() 等待回调。
GPU 显存架构 #
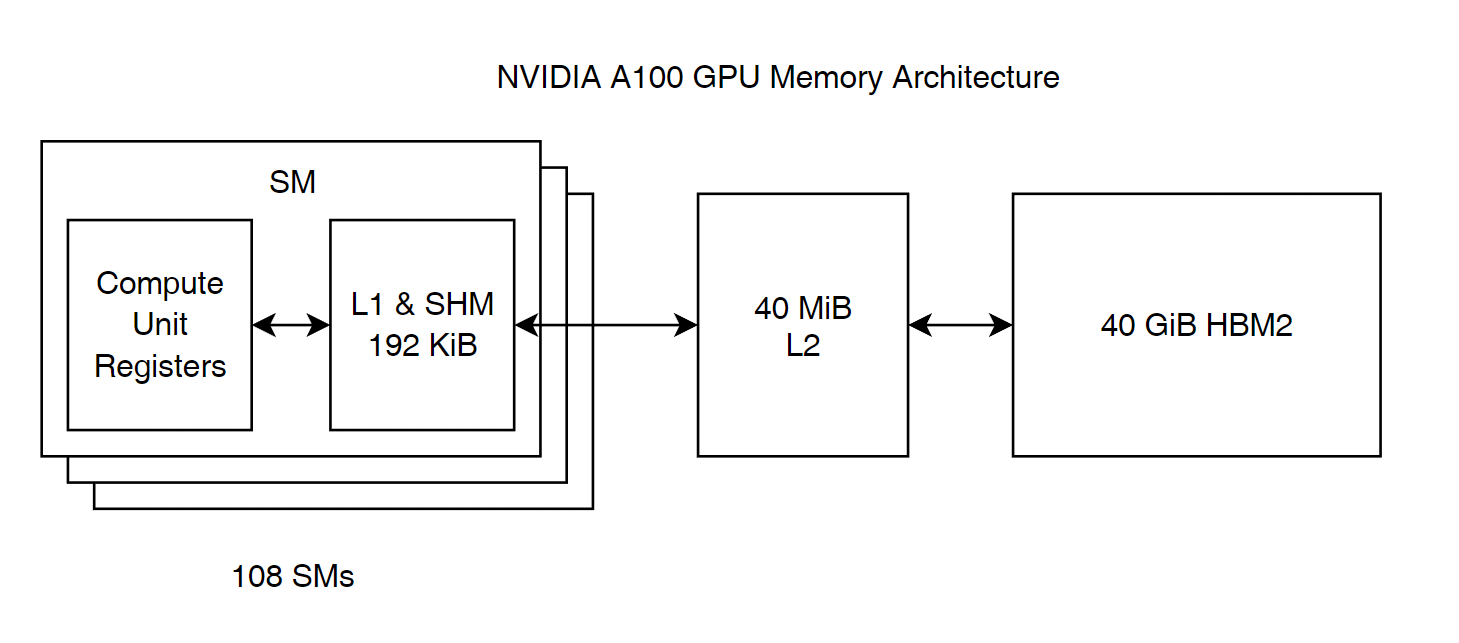
以 NVIDIA A100 GPU 为例,GPU 存储器也遵循金字塔原则。值得注意的是,Shared Memory 与 L1 缓存是共用 192 KiB 空间的。
Banks 与 Shared Memory #
如果想写出快速的 GPU 代码,就势必要用好 Shared Memory。但是 Bank 的问题会显著影响 Shared Memory 的性能,而 Global Memory 的问题就不那么显著。
根据刚才的架构图,可以看出 Shared Memory 是与 L1 缓存共用空间的。每个 Block 都有自己独立控制的 Shared Memory,所有 Block 中的 Thread 均可以访问。它具有较高的速度与较低的延迟,但是却有可能会造成冲突问题。
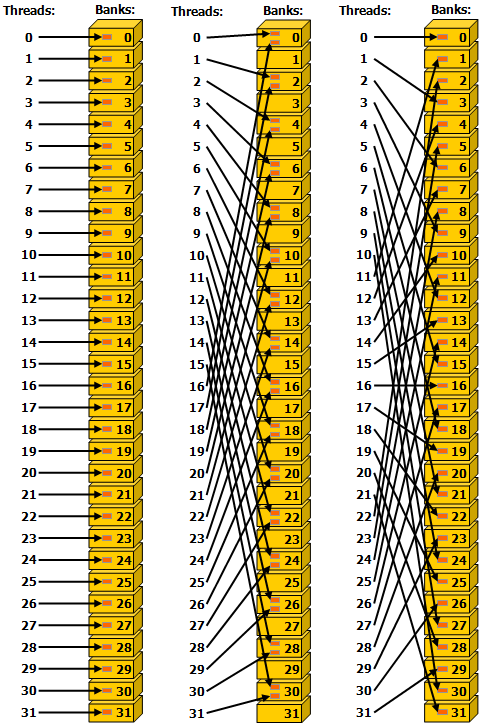
上图中,左右两侧的情况都没有冲突,每个 Thread 均访问一个 Bank。而中间的则出现了冲突,例如 Thread 0 与 16 均访问 Bank 0,这就导致了冲突。一个 Bank 在一个时钟周期内传输的数据量是有限的,因此整个程序就会被拖慢。
但值得注意的是,Broadcast 是可以的。当多个 Thread 访问同一个地址时,这个地址只会被一个 Thread 访问,然后被广播给其他需要的 Bank,再有其中一个 Thread 写回,这种情况下不会产生冲突。
如何写出正确且高效的 GPU 代码? #
- 管理好 GPU 与 CPU 之间的数据传输。 注意到 CPU 启动 Kernel 后并不会被堵塞,因此可以使其与 GPU 并行工作。
- 调整 Block 大小等参数。 由于单个 Kernel 运行速度比较快,因此可以写一个 for 循环暴力枚举以寻找最佳参数。
- 循环展开。
- 调整访存操作。 使用 Memory coalescing,避免 Bank conflict.
- 避免使用原子操作。 但是在 Shared Memory 里面进行原子操作是比较快的。
- 使用例如 Thrust, CUB, CuTensor, CuBLAS, CUTLASS 等官方的库。 一般情况下,这就是性能的上限。
- 有时候 PyTorch 也非常快。
- 使用软流水 (Software pipelining)。
下面简单介绍一下第一个与最后一个技巧:
管理 GPU 与 CPU 之间的数据传输 #
一般情况下,GPU 计算,CPU 计算,CPU 与 GPU 数据传输是可以同时进行的。如下图所示:
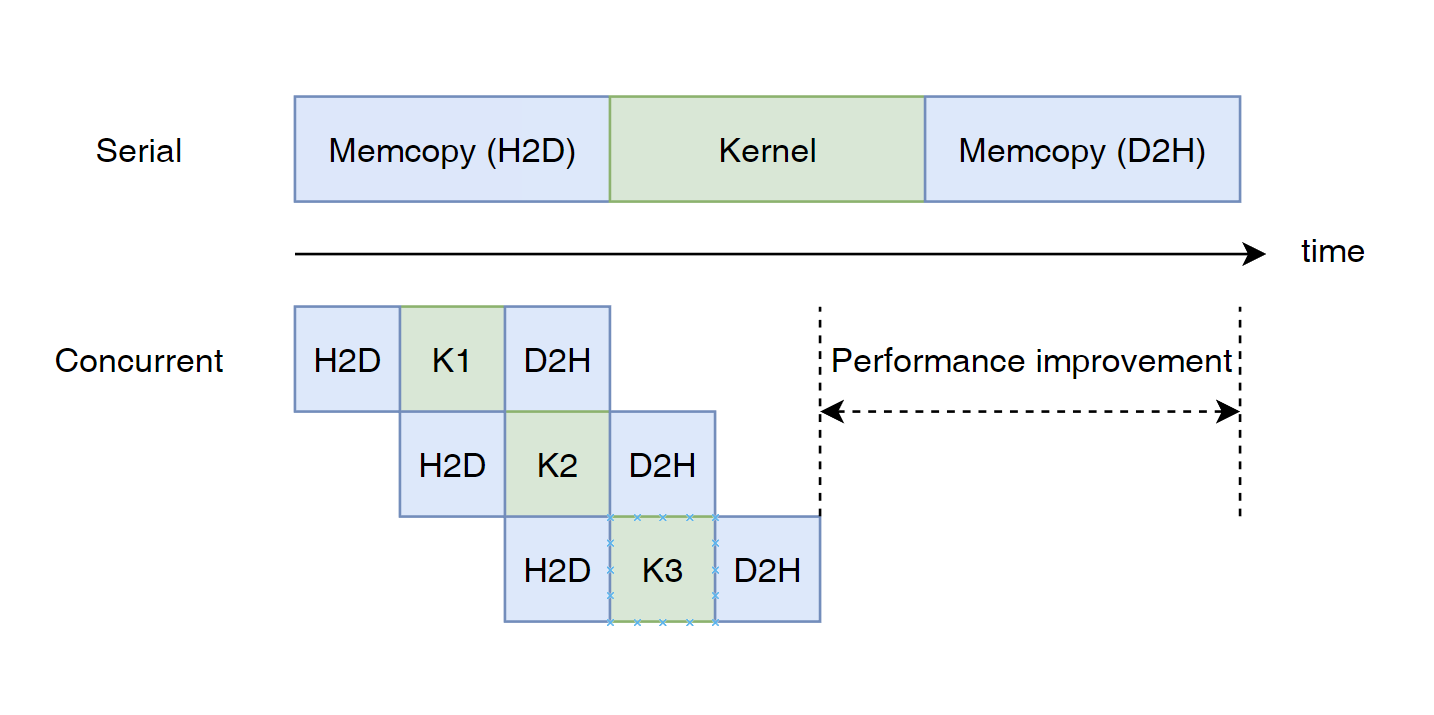
可以使用 cudaMallocHost, cudaFreeHost, cudaMemcpyAsync 以及 CUDA Stream 等 API 实现。
软流水 (Software pipelining) #
当使用 sqrt, cos tan, sigmoid 等数学函数或进行其他的耗时操作时,可以使用软流水操作。
实例:直方图 #
- 数组大小:512 MiB
u_char数据 - 区间个数:256
CPU 不加任何优化 - 350ms #
Code
void compute() {
for(int i = 0; i < ARRSZ; ++i) {
++bin[arr[i]];
}
}
CPU 并行 - 6s #
Code
void compute() {
#pragma omp parallel for num_threads(40)
for(int i = 0; i < ARRSZ; ++i) {
int c = arr[i];
#pragma omp atomic
++bin[c];
}
}
变慢的原因
开了 atomic 导致 40 个 Thread 竞争同一个操作。
CPU 并行改进版 - 200ms #
Code
void compute() {
#pragma omp parallel for num_threads (40)
for(int t = 0; t < 40; ++t) {
int tmp_bin[256] = {};
for(int i = t; i < ARRSZ; i += 40) {
int c = arr[i];
++tmp_bin[c];
}
for(int j = 0; j < 256; ++j) {
int a = tmp_bin[j] ;
#pragma omp atomic
bin[j] += a;
}
}
}
优化有限的原因
局部化不够是优化有限的原因。在这段代码中,每个 Thread 所取的两个数据之间都隔了 40 个数据,也就意味着每次访问内存获取到的数据都要被丢弃大半部分。
CPU 并行局部化改进版 - 45ms #
Code
void compute() {
int blk = (ARRSZ + 39) / 40;
#pragma omp parallel for num_threads (40)
for(int t = 0; t < 40; ++t) {
int tmp_bin[256] = {};
int l = blk * t, r = blk * (t + 1);
if(r > ARRSZ)
r = ARRSZ;
for(int i = l; i < r; ++i) {
int c = arr[i];
++tmp_bin[c];
}
for(int j = 0; j < 256; ++j) {
int a = tmp_bin[j] ;
#pragma omp atomic
bin[j] += a;
}
}
}
GPU 不加任何优化 - 213ms #
Code
__global__ void histogram_kernel_v1(unsigned char *array, unsigned int *bins) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
// we do not need to check boundary here as ARRSZ is a power of 2.
atomicAdd(&bins[array[tid]], 1u);
}
void compute() {
const int block_size = 256;
histogram_kernel_v1<<<ARRSZ / block_size, block_size>(arr_gpu, bin_gpu);
assert(cudaSuccess == cudaDeviceSynchronize());
}
GPU 循环展开 - 200ms #
Code
__global__ void histogram_kernel_v2(unsigned char *array, unsigned int *bins) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
unsigned int value_u32 = array[tid];
atomicAdd(&bins[value_u32 & 0x000000FF], 1u);
atomicAdd(&bins[(value_u32 & 0x0000FF00) >> 8], 1u);
atomicAdd(&bins[(value_u32 & 0x00FF0000) >> 16], 1u);
atomicAdd(&bins[(value_u32 & 0xFF000000) >> 24], 1u);
}
void compute() {
const int block_size = 256;
histogram_kernel_v2<<<ARRSZ / block_size / 4, block_size>((unsigned int*)arr_gpu, bin_gpu);
assert(cudaSuccess == cudaDeviceSynchronize());
}
优化有限的原因
循环展开后没有消除掉在 Global Memory 中进行 atomic 操作带来的竞争问题。
GPU 使用 Shared Memory 与循环展开 - 9ms #
Code
__shared__ unsigned int bins_shared[256];
__global__ void histogram_kernel_v3(unsigned char *array, unsigned int *bins) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
bins_shared[threadIdx.x] = 0;
__syncthreads();
unsigned int value_u32 = array[tid];
atomicAdd(&bins_shared[value_u32 & 0x000000FF], 1u);
atomicAdd(&bins_shared[(value_u32 & 0x0000FF00) >> 8], 1u);
atomicAdd(&bins_shared[(value_u32 & 0x00FF0000) >> 16], 1u);
atomicAdd(&bins_shared[(value_u32 & 0xFF000000) >> 24], 1u);
__syncthreads();
atomicAdd(&bins[threadIdx.x], bins_shared[threadIdx.x]);
}
void compute() {
const int block_size = 256;
histogram_kernel_v3<<<ARRSZ / block_size / 4, block_size>((unsigned int*)arr_gpu, bin_gpu);
assert(cudaSuccess == cudaDeviceSynchronize());
}
GPU 使用 Shared Memory 与更多的循环展开 - <1ms #
Code
__shared__ unsigned int bins_shared[256];
const int N = 32;
__global__ void histogram_kernel_v4(unsigned char *array, unsigned int *bins) {
int toffset = blockIdx.x * blockDim.x + threadIdx.x;
int sz = gridDim.x * blockDim.x;
bins_shared[threadIdx.x] = 0;
__syncthreads();
for(int i = 0, tid = toffset; i < N; ++i, tid += sz) {
unsigned int value_u32 = array[tid];
atomicAdd(&bins_shared[value_u32 & 0x000000FF], 1u);
atomicAdd(&bins_shared[(value_u32 & 0x0000FF00) >> 8], 1u);
atomicAdd(&bins_shared[(value_u32 & 0x00FF0000) >> 16], 1u);
atomicAdd(&bins_shared[(value_u32 & 0xFF000000) >> 24], 1u);
}
__syncthreads();
atomicAdd(&bins[threadIdx.x], bins_shared[threadIdx.x]);
}
void compute() {
const int block_size = 256;
histogram_kernel_v4<<<ARRSZ / block_size / 4 / N, block_size>((unsigned int*)arr_gpu, bin_gpu);
assert(cudaSuccess == cudaDeviceSynchronize());
}
优化的原因
减少了在 Global Memory 中进行 atomic 操作的次数。